
OpenEBS-For-MinIO
Architecture
Architecture

Images From Openebs Preface About OpenEBS OpenEBS is an open source storage project running on Kubernets, in line with the CAS (Container Attached Storage) architecture. All of its components run at the user level and belong to the cloud-native distributed file system on k8s. OpenEBS file system provides the following categories of features , each feature can be used in a particular environment solution . cStor: supports fault tolerance, high availability, replica copy, snapshot, clone, etc. Its backend is supported by ZFS. ...
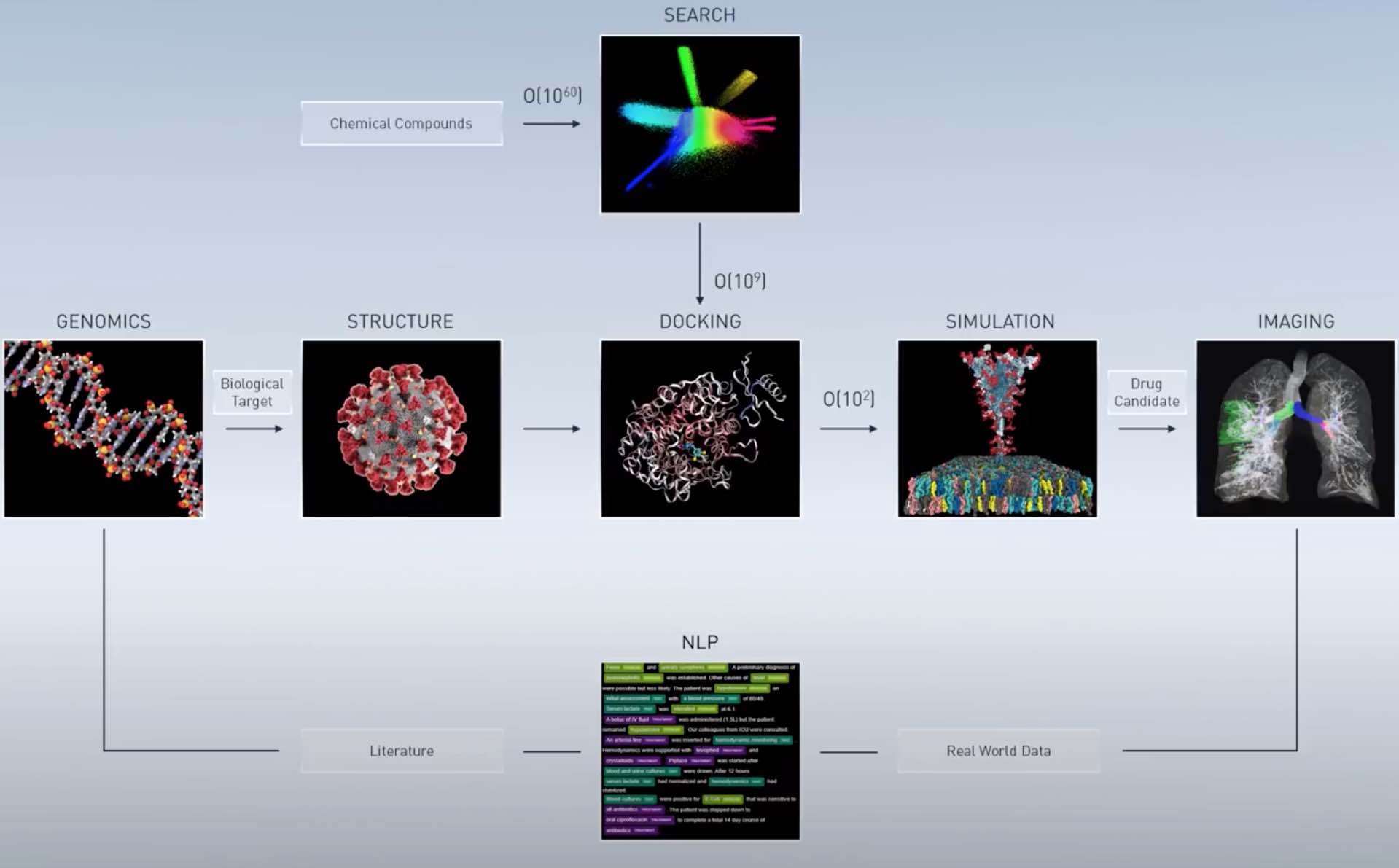
NVIDIA CLARA DISCOVERY Eco Nvidia’s entry into the medical field. From the cover we can see a ring structure: Natural Language -> Viral Gene Sequence -> Viral Protein Structure -> New Drug Docking with Viral Protein -> Molecular Docking Dynamics Simulation -> Clinical Trial of Drug Candidate Detecting Medical Images of Patient’s Lungs -> Natural Language Introduction At the Nvidia GTC 2020 Fall Conference, Nvidia announced the NVIDIA CLARA DISCOVERY drug development framework, which aims to accelerate the progress of global drug development. With the news of Nvidia’s acquisition of ARM before, I realized that Nvidia has the ambition to rule the edge computing field in the future. Not surprisingly, this GTC conference Nvidia updated many product lines, including large to data center computing module BlueField-2, small to edge field jetson Nano 2G, the most exciting for me is still ** CLARA DISCOVERY**, because my own short-term goal is how to use edge computing in the medical field, such as individuals can calculate the current status of their own diseases through edge computing devices combined with their own diagnostic data obtained from hospital examinations, as well as judgmental detection of Covid-19 CT, ChestXRay. ...

Summary This article will not go into too much technical details about ETH, but will mainly deal with how to become a validator of ETH 2.0. At the end of this year, ETH will complete the stage 0 upgrade, migrating from PoW proof-of-work to PoS proof-of-stake. Before myself at the company’s hackathon com , I thought about how to use the excess arithmetic power to do something valuable. PoW is theoretically more wasteful of energy, and miners buy a lot of mining machines for computing, while after adopting the PoS mechanism, by becoming a validator, we can finish the Instead of buying a lot of mining machines to generate new blocks like PoW, to become a validator you need to lock a certain amount of cryptocurrency as proof of interest, if you run a verifying node to verify a block and check if all the transactions inside are valid, if it passes, you will receive a reward in return. ...
Sidebar Behind why deep learning is so powerful, we can think of the human brain’s neurons, which individually can’t do anything, but a bunch of neurons together are immensely powerful. Watch a movie about how cells and proteins work in living things, and be amazed at how tiny microscopic worlds can work in such subtle ways. Inner Life Of A Cell - Full Version Sometimes when I think about the above questions, I get the urge to learn more about how the world works, whether human communication can be likened to molecular interactions, why a bunch of >neurons put together can create intelligent life forms, how the free consciousness of such life forms is formed, how the transfer of information between neurons is encoded, and what is happening at a deeper level. Whether the field of study can continue to exploit certain features of the brain > neurons to enhance the design of models. ...