MPICH Raspberry Pi Cluster
The earliest project to run MPICH on a Raspberry Pi cluster would be Raspberry Pi at Southampton, in which professor Simon Cox and his son together to build an MPI cluster consisting of 64 Raspberry Constructs and Legos. This project is already 10 years old, and at that time the raspberry pi 1 B+ was used, and due to the limitations of the performance of the 1st generation, the whole cluster could only be used for MPI learning, which is still under-utilized in high-performance computing. However, now raspberry pi 4 is still very weak compared to Intel servers, but it still has great potential to run MPICH related computing projects compared to the 1st generation. First of all, power consumption, 64 raspberry pi 4 CPUs running at full load consume about 400 watts, and secondly, the ARM ecosystem is now very well developed compared to a decade ago, and a lot of programs have been ported to the ARM64 platform, with a variety of tools at your fingertips.
One of the most outstanding projects recently must be Meta LLaMA V2, based on the previous generation of models, LLaMA 2 is open for commercial license, so is it possible to run the LLaMA 2 LLM model on a raspberry pi 4 cluster? project [llama The project llama.cpp has given the answer. llama.cpp quantizes the llama native model parameter type from float 16bit to int 4bit, which enables the large language model to run on consumer level hardware CPU/GPUs .
Deployment LLaMA.cpp on raspberry pi k8s cluster
A long time ago I set up a raspberry pi 4 cluster at home, the node size is at 70 units and is still running, the cluster uses k8s for management, so in conjunction with volcano, llama.cpp was deployed on the raspberry pi nodes, and the cluster network distributed file system I’m currently using is moosefs.

-
First deploy volcano, it is equivalent to a k8s task scheduler, which can be used for distributed training of deep learning and high-performance parallel computing, the deployment can be referred to volcano github
-
Build MPICH llama.cpp docker image
FROM ubuntu:22.04
ENV DEBIAN_FRONTEND=noninteractive
RUN apt update && apt upgrade -y && apt-get install build-essential gfortran make cmake wget zip unzip python3-pip python3-dev gfortran liblapack-dev pkg-config libopenblas-dev autoconf python-is-python3 vim -y
# compile mpich
WORKDIR /tmp
RUN wget https://www.mpich.org/static/downloads/4.1.2/mpich-4.1.2.tar.gz
RUN tar xf mpich-4.1.2.tar.gz
RUN cd mpich-4.1.2 && ./configure --prefix=/usr && make -j $(nproc) && make install
RUN rm -rf mpich-4.1.2.tar.gz mpich-4.1.2
# compile llama.cpp
RUN apt install git -y
WORKDIR /
ENV LLAMA_CPP_GIT_UPDATE 2023-07-19
RUN git clone https://github.com/ggerganov/llama.cpp.git
RUN cd llama.cpp && make CC=mpicc CXX=mpicxx LLAMA_MPI=1 LLAMA_OPENBLAS=1
RUN cd llama.cpp && python3 -m pip install -r requirements.txt
RUN apt install openssh-server -y && mkdir -p /var/run/sshd
ENV PATH=/llama.cpp:$PATH
- RUN MPI Job
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: llama-mpi-job
labels:
"volcano.sh/job-type": "MPI"
spec:
minAvailable: 5
schedulerName: volcano
plugins:
ssh: []
svc: []
policies:
- event: PodEvicted
action: RestartJob
tasks:
- replicas: 1
name: mpimaster
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
volumes:
- name: mfs
hostPath:
path: /mfs
type: Directory
containers:
- command:
- /bin/sh
- -c
- |
export MPI_HOST=`cat /etc/volcano/mpiworker.host | tr "\n" ","`;
mkdir -p /var/run/sshd; /usr/sbin/sshd;
sleep infinity;
# please fill your llama mpich docker image that build in step 2.
image: registry.cineneural.com/compile-projects/llama-cpp-arm64-cpu:ubuntu22.04
imagePullPolicy: Always
name: mpimaster
volumeMounts:
- mountPath: /mfs
name: mfs
ports:
- containerPort: 22
name: mpijob-port
resources:
requests:
cpu: 2
memory: "2Gi"
limits:
cpu: "4"
memory: "2Gi"
restartPolicy: OnFailure
- replicas: 10
name: mpiworker
template:
spec:
volumes:
- name: mfs
hostPath:
path: /mfs
type: Directory
containers:
- command:
- /bin/sh
- -c
- |
mkdir -p /var/run/sshd; /usr/sbin/sshd -D;
# please fill your llama mpich docker image that build in step 2.
image: registry.cineneural.com/compile-projects/llama-cpp-arm64-cpu:ubuntu22.04
imagePullPolicy: Always
name: mpiworker
volumeMounts:
- mountPath: /mfs
name: mfs
ports:
- containerPort: 22
name: mpijob-port
resources:
requests:
cpu: "2"
memory: "2Gi"
limits:
cpu: "4"
memory: "4Gi"
restartPolicy: OnFailure
- Convert Llama 2 Models to GGML Bin file
# LLaMA 2 13B Chat Model
python3 convert.py --outtype f16 /mfs/packages/Meta/LLaMA-v2-models/llama-2-13b-chat
quantize /mfs/packages/Meta/LLaMA-v2-models/llama-2-13b-chat/ggml-model-f16.bin \
/mfs/packages/Meta/LLaMA-v2-models/llama-2-13b-chat/ggml-model-q4_0.bin q4_0
# LLaMA 1 7B Model
python3 convert.py --outtype f16 /mfs/packages/Meta/LLaMA-v1-models/7B
quantize /mfs/packages/Meta/LLaMA-v1-models/7B/ggml-model-f16.bin \
/mfs/packages/Meta/LLaMA-v1-models/7B/ggml-model-q4_0.bin q4_0
- Inference
kubectl exec -ti llama-mpi-job-mpimaster-0 bash
# run command line in llama-mpi-job-mpimaster-0 container:
mpirun -hostfile /etc/volcano/mpiworker.host -n 5 \
/llama.cpp/main \
-m /mfs/packages/Meta/LLaMA-v2-models/llama-2-13b-chat/ggml-model-q4_0.bin \
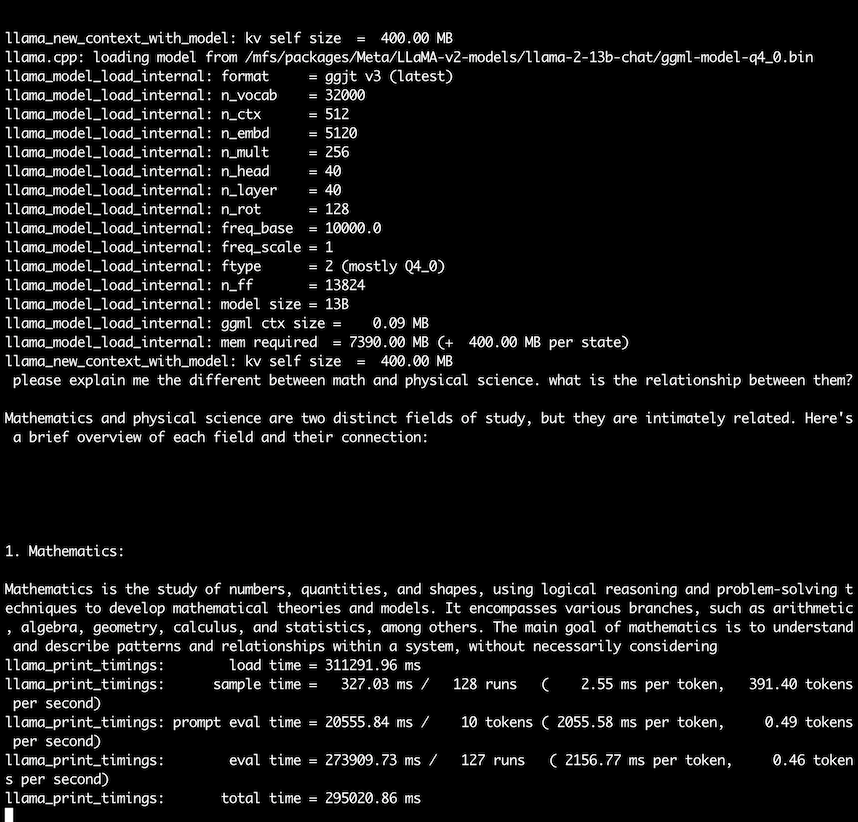
-p "please explain me the different between math and physical" -n 128
Chat with Raspberry Pi
llama v1
7B
mpirun -hostfile /etc/volcano/mpiworker.host \
-n 5 /llama.cpp/main \
-m /mfs/packages/Meta/LLaMA-v1-models/7B/ggml-model-q4_0.bin \
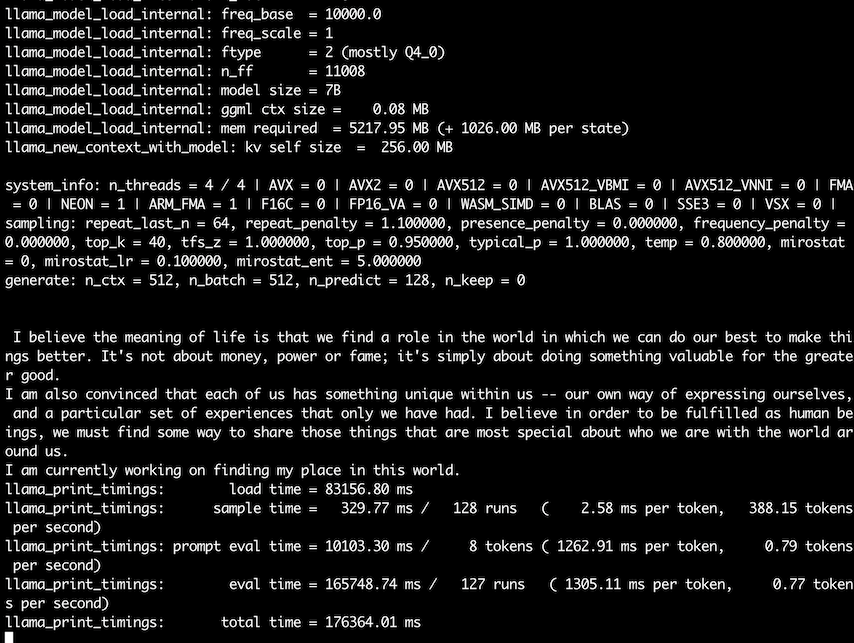
-p "I believe the meaning of life is" -n 128
mpirun -hostfile /etc/volcano/mpiworker.host \
-n 5 /llama.cpp/main \
-m /mfs/packages/Meta/LLaMA-v1-models/7B/ggml-model-q4_0.bin \
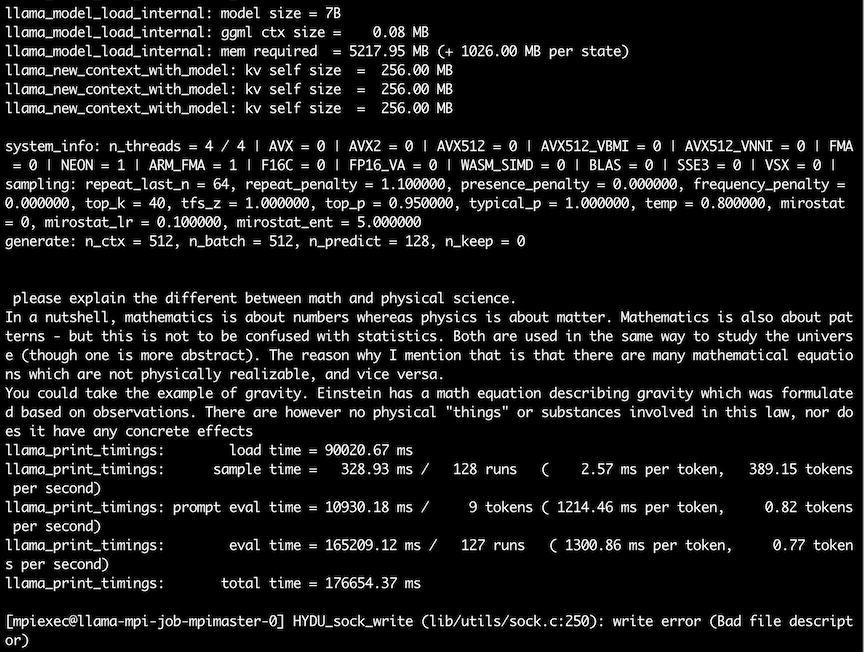
-p "please explain the different between math and physical" -n 128
mpirun -hostfile /etc/volcano/mpiworker.host \
-n 5 /llama.cpp/main \
-m /mfs/packages/Meta/LLaMA-v1-models/7B/ggml-model-q4_0.bin \
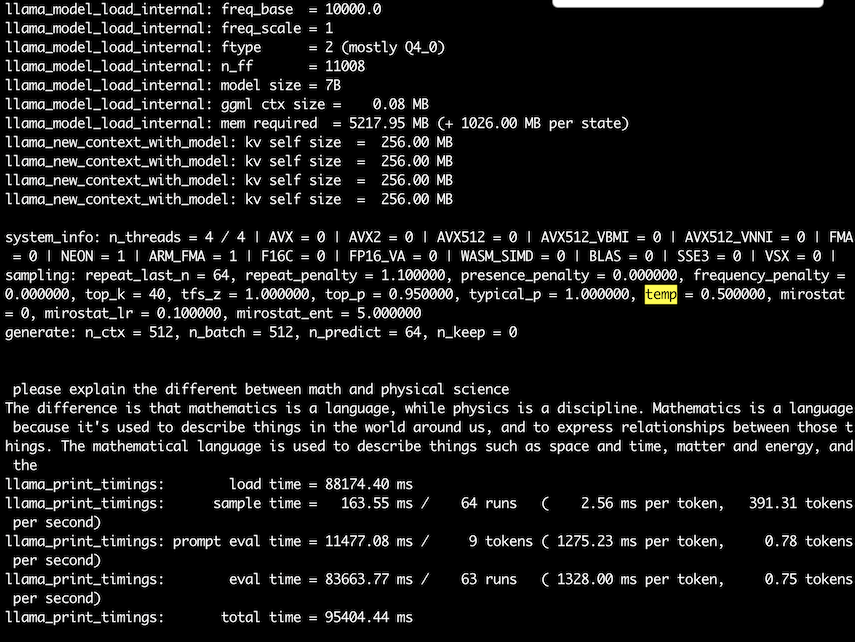
-p "please explain the different between math and physical" -n 64 --temp 0.5
llama v2
7B Chat
mpirun -hostfile /etc/volcano/mpiworker.host -n 5 /llama.cpp/main
-m /mfs/packages/Meta/LLaMA-v2-models/llama-2-7b-chat/ggml-model-q4_0.bin \
-p "I believe the meaning of life is" -n 128
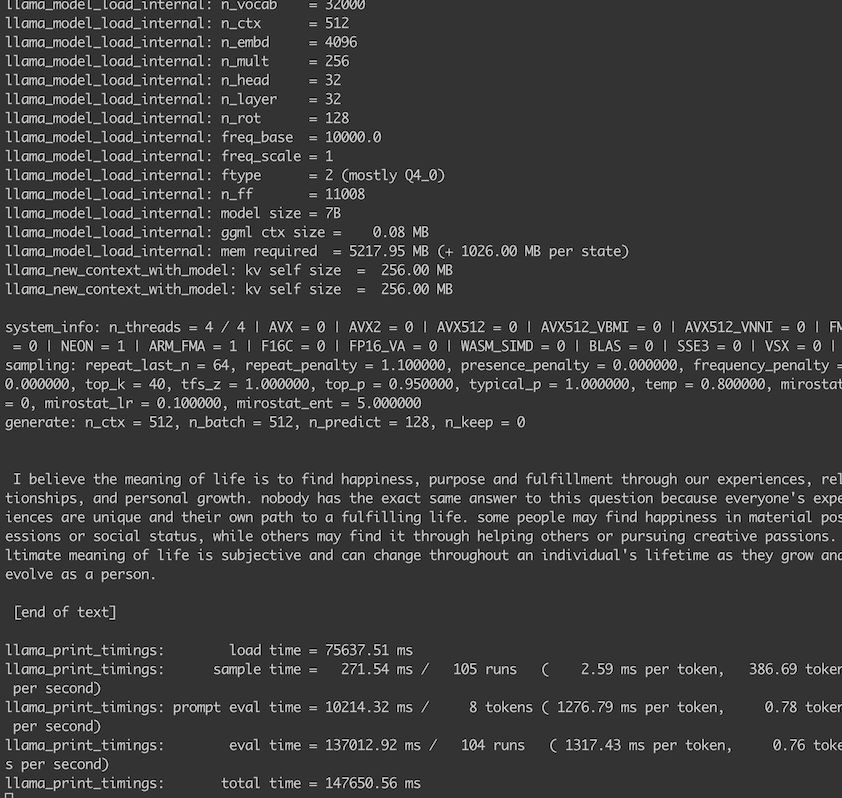
mpirun -hostfile /etc/volcano/mpiworker.host -n 5 \
/llama.cpp/main -m /mfs/packages/Meta/LLaMA-v2-models/llama-2-7b-chat/ggml-model-q4_0.bin \
-p "please explain the different between math and physical" -n 128
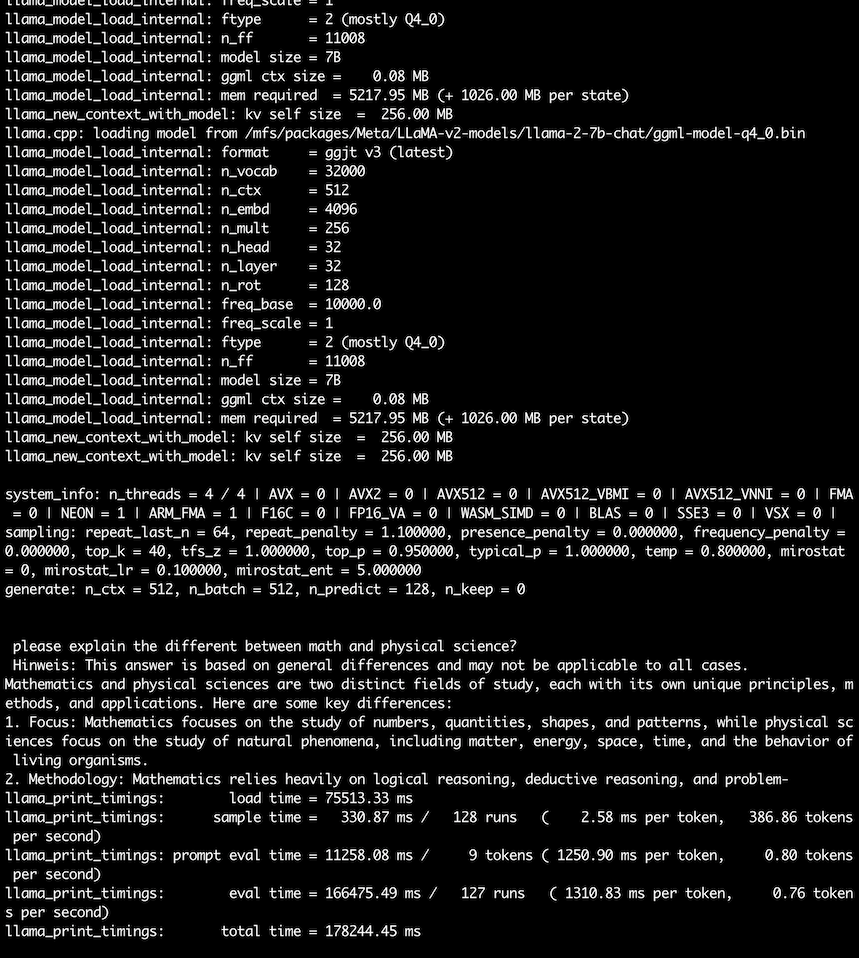
13B Chat
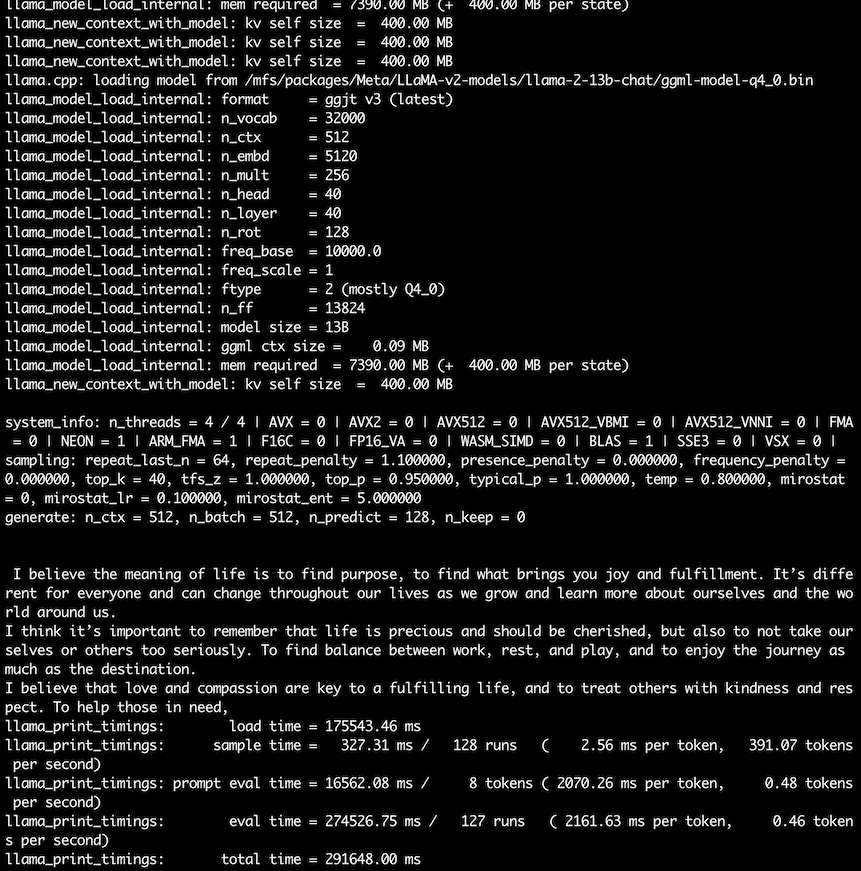
mpirun -hostfile /etc/volcano/mpiworker.host -n 7 \
/llama.cpp/main -m /mfs/packages/Meta/LLaMA-v2-models/llama-2-13b-chat/ggml-model-q4_0.bin \
-p "I believe the meaning of life is" -n 128
mpirun -hostfile /etc/volcano/mpiworker.host -n 7
/llama.cpp/main -m /mfs/packages/Meta/LLaMA-v2-models/llama-2-13b-chat/ggml-model-q4_0.bin
-p "please explain me the different between math and physical" -n 128