
Coral ecology and technology
References: Coral AI
Introducing the entire ecosystem of google coral edge TPU computing.

-
SoM for production environment and PCIe Accelerator.
-
Four pocket-sized development boards for development and testing.
-
Peripheral sensors including environmental detection module as well as camera, Wi-Fi/PoE expansion board.
Cloud TPU / Edge TPU Introduction
Technology

Coral Edge TPU is a dedicated chip developed by Google to accelerate neural network inference in edge devices and run specially optimized neural network models while maintaining low power consumption.

Edge TPU runs at 4 Tops and consumes 0.5W/Tops, which is equivalent to a total power consumption of 48WH a day if Edge TPU runs at full load all day, so that low power consumption is definitely an advantage for the requirements of industrial environments. The above figure shows the comparison of embedded CPU and Edge TPU inference speed. It can be seen that the running time on edge TPU is much lower than embedded cpu, reducing power consumption but maintaining the accuracy of model inference and accelerating operation, which is the advantage of edge tpu in industrial field.
Scalability
Coral product line includes the initial prototyping development board, to the product PCI edge TPU module, and finally to the micro controller micro dev board, the entire ecological chain are supplied, the disadvantage is that due to chip restrictions in China is difficult to buy, foreign because of the relationship between production reasons, but also need to keep an eye on the supplier’s inventory. Like the Environmental Sensor Board I bought before, it was purchased through HK and the micro dev board was shipped from EU to China through pi3g supplier.
Model compatibility
edge TPU can run models built by tensorflow and keras, of course the model needs to be converted to int8 tensorflow lite, this step is called quantized, so as to reduce the memory overhead of the model on the edge device, then the tflite model is compiled by the edge tpu compiler and finally run on the edge tpu.
Mendel Linux
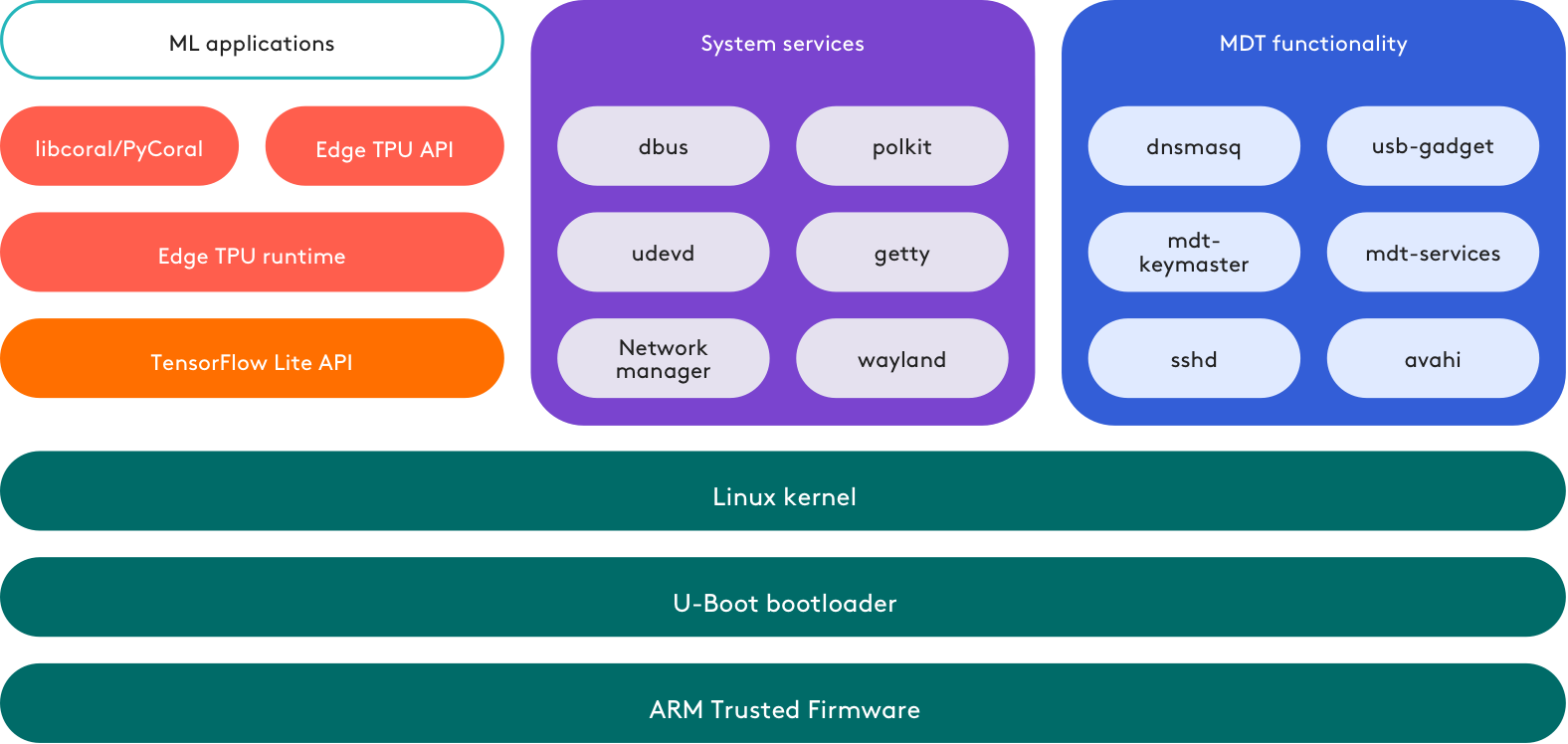
Coral Dev Board and Coral Dev Mini Board and SoM can run google’s own maintenance of Mendel Linux, the disadvantage of the system is too independent, using the linux kernel is 4.x series, compared to the raspberry pi ecology, coral’s kernel is quite old, and can not use the new features of the linux kernel, and like raspberry pi official support has been the Linux kernel to 6.x series. In terms of programming interface, google provides, pycoral + libcoral, and the shell command line tool MDT.
Coral Micro
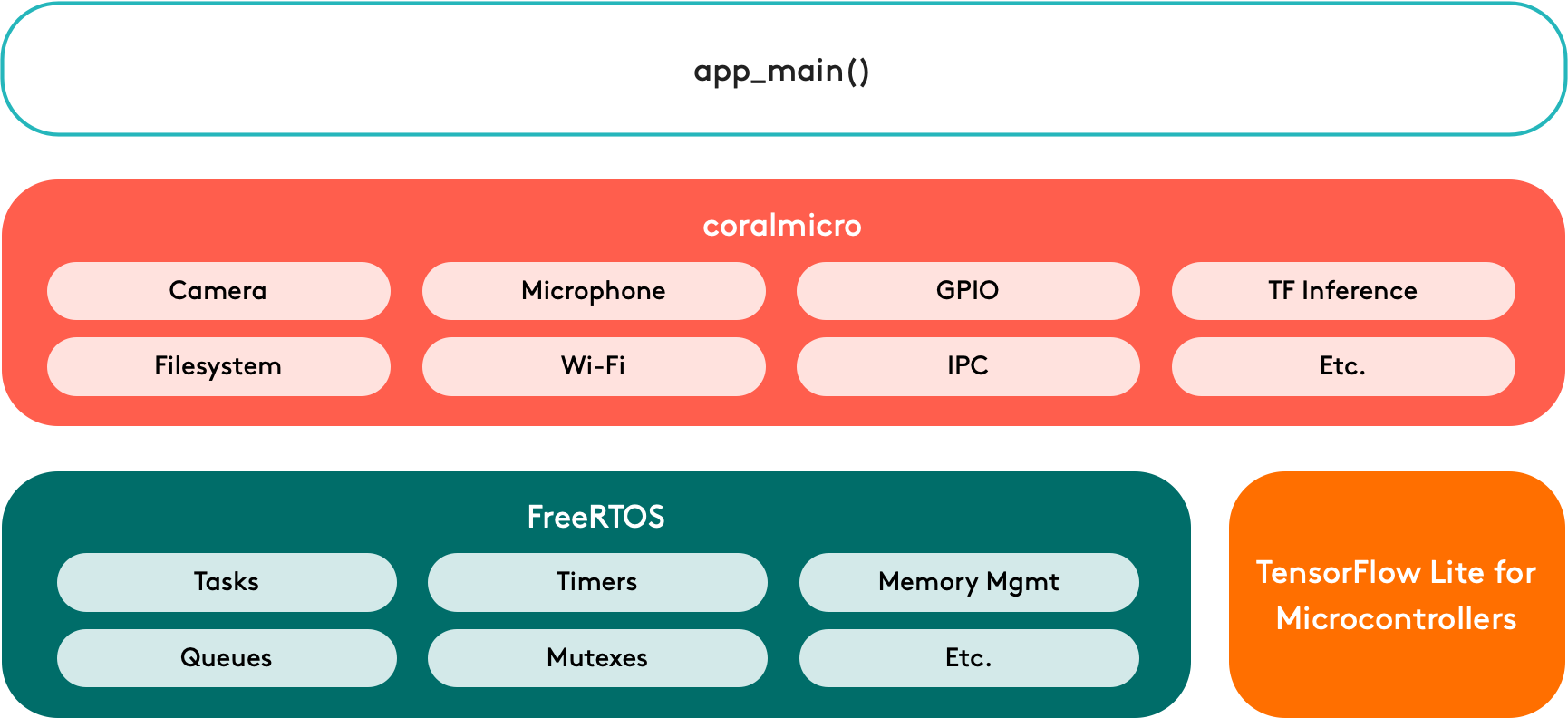
Dev Board Micro is a microcontroller development board running the freeRTOS-based CoralMicro system with programming environment support for Arduino and C++/CMakefile, and CoralMicro is open source.
Run multiple models
If there is only a single edge tpu, multiple models can share the edge tpu memory through the co-compiling technique. If there are multiple edge tpus, then each model can be run separately on the corresponding edge tpu in parallel.
Model pipeline
Splitting a model into multiple parts to run on different edge tpu can speed up inference, while for a large model run on a single edge tpu can break the case of not being able to run due to memory limitations.
On-device training
The edge tpu is suitable for model inference. Due to hardware constraints it is not possible to do the training of the entire model weights, but it is possible to train the last layer of the network on the edge tpu by freezing all the weights beyond the last layer of the neural network through migration learning to train a model that meets the requirements.
Future
Since the chatGPT access to the public area, the hottest industry discussion today is of course AI, big models + big data, if you want to train a model like chatGPT, the hardware cost is quite high for small and medium-sized companies, as well as the model design and development investment is a considerable expense, unless companies directly purchase and use services like chatGPT, DALL-E with a fee-based subscription services. Now we focus on small areas, such as running models on embedded devices, solving the problems encountered in industrialization, trying to reduce the cost of inference equipment, reduce power consumption, so that it can penetrate into various fields, which was called tinyML. In tinyML what chip to run neural network inference, my answer is Edge TPU, although the current Google coral users is not as many as Nvidia jetson, but the future of running AI on the microcontroller is definitely a dedicated chip, edge TPU main advantage is low power consumption, low latency, high efficiency.