MPICH Raspberry Pi Cluster
最早在Raspberry Pi集群上运行MPICH的项目应该是Raspberry Pi at Southampton,教授Simon Cox和他的儿子一起搭建由64个树莓构和乐高积木构成的MPI集群,这个项目已经是10年前的了,那个时候使用的是raspberry pi 1 B+,由于1代性能的限制,整个集群只能用于MPI学习,在高性能计算方面还是欠佳。然而现在raspberry pi 4虽然对比Intel服务器而言性能还是很弱,但是运行MPICH相关的计算项目比起1代还是非常有潜力的。首先是功耗方面,64块raspberry pi 4 CPU满载运行总功耗大概400多瓦左右,其次是ARM生态比起十年前现在已经非常完善,很多的程序都已经被移植到了ARM64平台上,各种各样的工具垂手可得。
最近比较出类拔萃的项目一定属于Meta LLaMA V2,在上一代模型的基础上,LLaMA 2 开放了商业使用许可,那么能否在raspberry pi 4 cluster上运行LLaMA 2 LLM 模型呢?项目llama.cpp已经给出了答案。llama.cpp将llama原生模型参数类型从float 16bit量化到int 4bit,从而使得大语言模型能够运行在消费级的CPU/GPU上。
Deployment LLaMA.cpp on raspberry pi k8s cluster
很早之前我在家里搭建了一套raspberry pi 4集群,节点规模在70台,并且目前还在运行中,集群采用k8s来进行管理,于是结合volcano,将llama.cpp部署在raspberry pi 节点上,节点间的共享存储我目前采用的是moosefs。

-
首先部署volcano,它相当于一个k8s任务调度器,可用于深度学习的分布式训练以及高性能的并行计算,部署可以参考volcano github
-
构建MPICH llama.cpp docker image
FROM ubuntu:22.04
ENV DEBIAN_FRONTEND=noninteractive
RUN apt update && apt upgrade -y && apt-get install build-essential gfortran make cmake wget zip unzip python3-pip python3-dev gfortran liblapack-dev pkg-config libopenblas-dev autoconf python-is-python3 vim -y
# compile mpich
WORKDIR /tmp
RUN wget https://www.mpich.org/static/downloads/4.1.2/mpich-4.1.2.tar.gz
RUN tar xf mpich-4.1.2.tar.gz
RUN cd mpich-4.1.2 && ./configure --prefix=/usr && make -j $(nproc) && make install
RUN rm -rf mpich-4.1.2.tar.gz mpich-4.1.2
# compile llama.cpp
RUN apt install git -y
WORKDIR /
ENV LLAMA_CPP_GIT_UPDATE 2023-07-19
RUN git clone https://github.com/ggerganov/llama.cpp.git
RUN cd llama.cpp && make CC=mpicc CXX=mpicxx LLAMA_MPI=1 LLAMA_OPENBLAS=1
RUN cd llama.cpp && python3 -m pip install -r requirements.txt
RUN apt install openssh-server -y && mkdir -p /var/run/sshd
ENV PATH=/llama.cpp:$PATH
- 运行MPI Job
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: llama-mpi-job
labels:
"volcano.sh/job-type": "MPI"
spec:
minAvailable: 5
schedulerName: volcano
plugins:
ssh: []
svc: []
policies:
- event: PodEvicted
action: RestartJob
tasks:
- replicas: 1
name: mpimaster
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
volumes:
- name: mfs
hostPath:
path: /mfs
type: Directory
containers:
- command:
- /bin/sh
- -c
- |
export MPI_HOST=`cat /etc/volcano/mpiworker.host | tr "\n" ","`;
mkdir -p /var/run/sshd; /usr/sbin/sshd;
sleep infinity;
# please fill your llama mpich docker image that build in step 2.
image: registry.cineneural.com/compile-projects/llama-cpp-arm64-cpu:ubuntu22.04
imagePullPolicy: Always
name: mpimaster
volumeMounts:
- mountPath: /mfs
name: mfs
ports:
- containerPort: 22
name: mpijob-port
resources:
requests:
cpu: 2
memory: "2Gi"
limits:
cpu: "4"
memory: "2Gi"
restartPolicy: OnFailure
- replicas: 10
name: mpiworker
template:
spec:
volumes:
- name: mfs
hostPath:
path: /mfs
type: Directory
containers:
- command:
- /bin/sh
- -c
- |
mkdir -p /var/run/sshd; /usr/sbin/sshd -D;
# please fill your llama mpich docker image that build in step 2.
image: registry.cineneural.com/compile-projects/llama-cpp-arm64-cpu:ubuntu22.04
imagePullPolicy: Always
name: mpiworker
volumeMounts:
- mountPath: /mfs
name: mfs
ports:
- containerPort: 22
name: mpijob-port
resources:
requests:
cpu: "2"
memory: "2Gi"
limits:
cpu: "4"
memory: "4Gi"
restartPolicy: OnFailure
- 将llama 2模型文件转换到ggml bin
# LLaMA 2 13B Chat Model
python3 convert.py --outtype f16 /mfs/packages/Meta/LLaMA-v2-models/llama-2-13b-chat
quantize /mfs/packages/Meta/LLaMA-v2-models/llama-2-13b-chat/ggml-model-f16.bin \
/mfs/packages/Meta/LLaMA-v2-models/llama-2-13b-chat/ggml-model-q4_0.bin q4_0
# LLaMA 1 7B Model
python3 convert.py --outtype f16 /mfs/packages/Meta/LLaMA-v1-models/7B
quantize /mfs/packages/Meta/LLaMA-v1-models/7B/ggml-model-f16.bin \
/mfs/packages/Meta/LLaMA-v1-models/7B/ggml-model-q4_0.bin q4_0
- 推理
kubectl exec -ti llama-mpi-job-mpimaster-0 bash
# run command line in llama-mpi-job-mpimaster-0 container:
mpirun -hostfile /etc/volcano/mpiworker.host -n 5 \
/llama.cpp/main \
-m /mfs/packages/Meta/LLaMA-v2-models/llama-2-13b-chat/ggml-model-q4_0.bin \
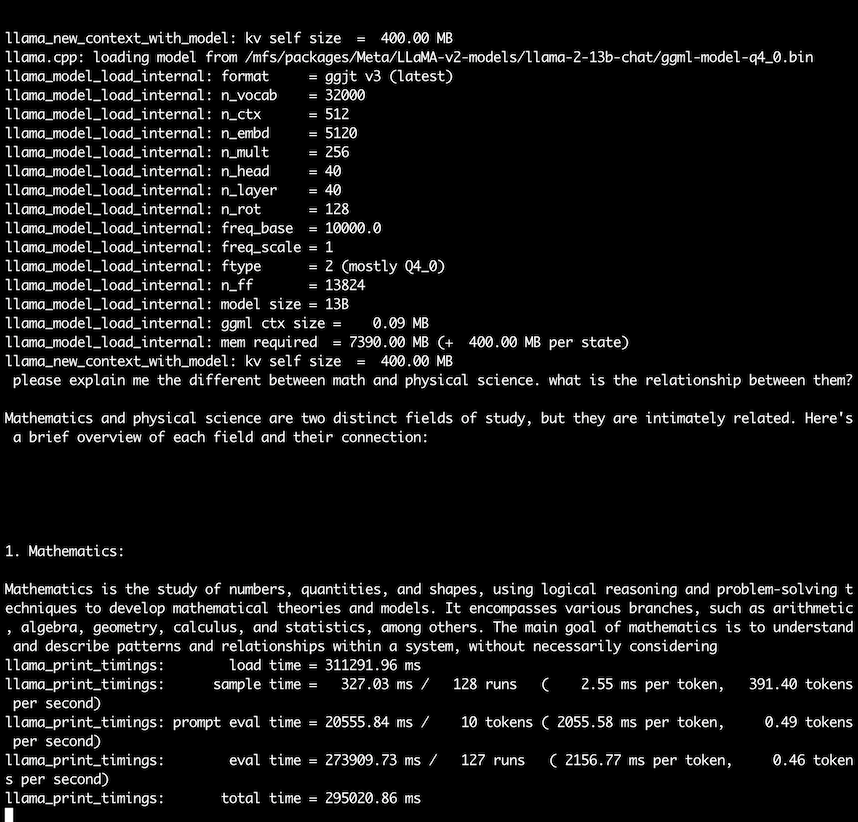
-p "please explain me the different between math and physical" -n 128
Chat with Raspberry Pi
llama v1
7B
mpirun -hostfile /etc/volcano/mpiworker.host \
-n 5 /llama.cpp/main \
-m /mfs/packages/Meta/LLaMA-v1-models/7B/ggml-model-q4_0.bin \
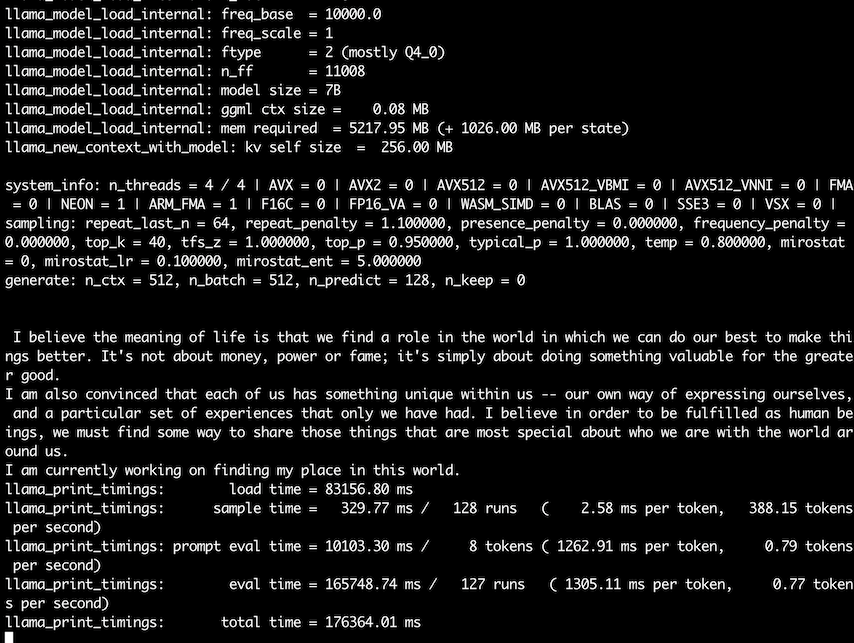
-p "I believe the meaning of life is" -n 128
mpirun -hostfile /etc/volcano/mpiworker.host \
-n 5 /llama.cpp/main \
-m /mfs/packages/Meta/LLaMA-v1-models/7B/ggml-model-q4_0.bin \
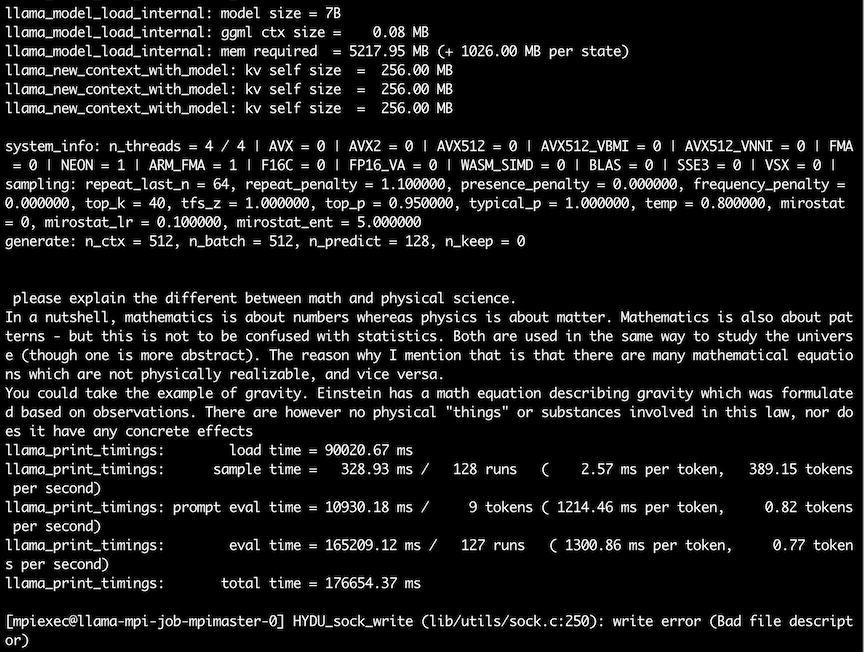
-p "please explain the different between math and physical" -n 128
mpirun -hostfile /etc/volcano/mpiworker.host \
-n 5 /llama.cpp/main \
-m /mfs/packages/Meta/LLaMA-v1-models/7B/ggml-model-q4_0.bin \
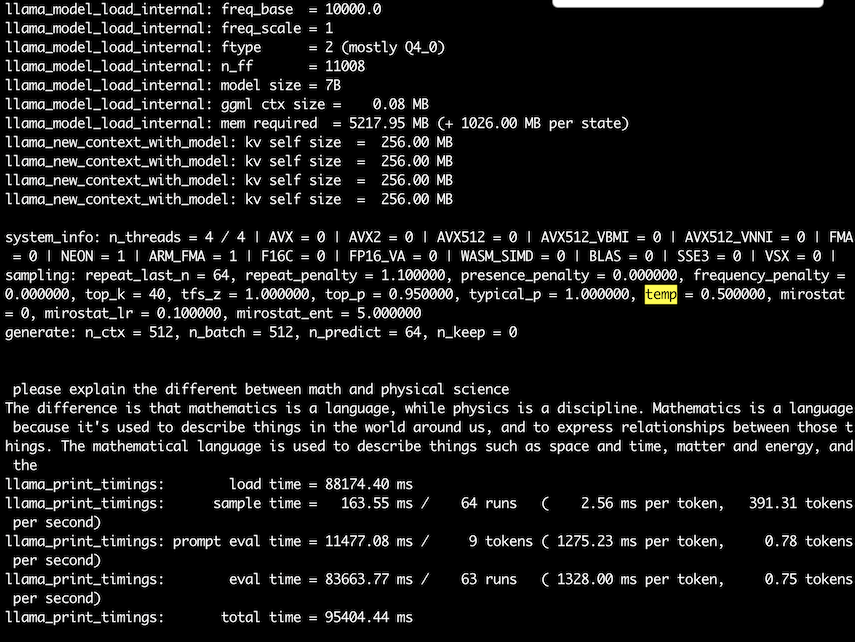
-p "please explain the different between math and physical" -n 64 --temp 0.5
llama v2
7B Chat
mpirun -hostfile /etc/volcano/mpiworker.host -n 5 /llama.cpp/main
-m /mfs/packages/Meta/LLaMA-v2-models/llama-2-7b-chat/ggml-model-q4_0.bin \
-p "I believe the meaning of life is" -n 128
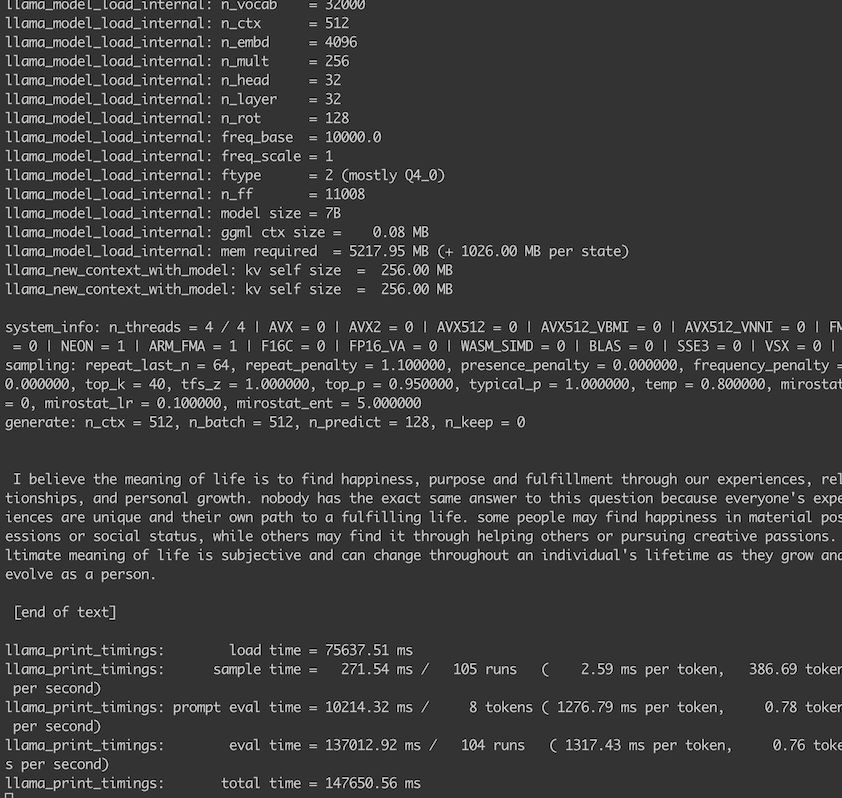
mpirun -hostfile /etc/volcano/mpiworker.host -n 5 \
/llama.cpp/main -m /mfs/packages/Meta/LLaMA-v2-models/llama-2-7b-chat/ggml-model-q4_0.bin \
-p "please explain the different between math and physical" -n 128
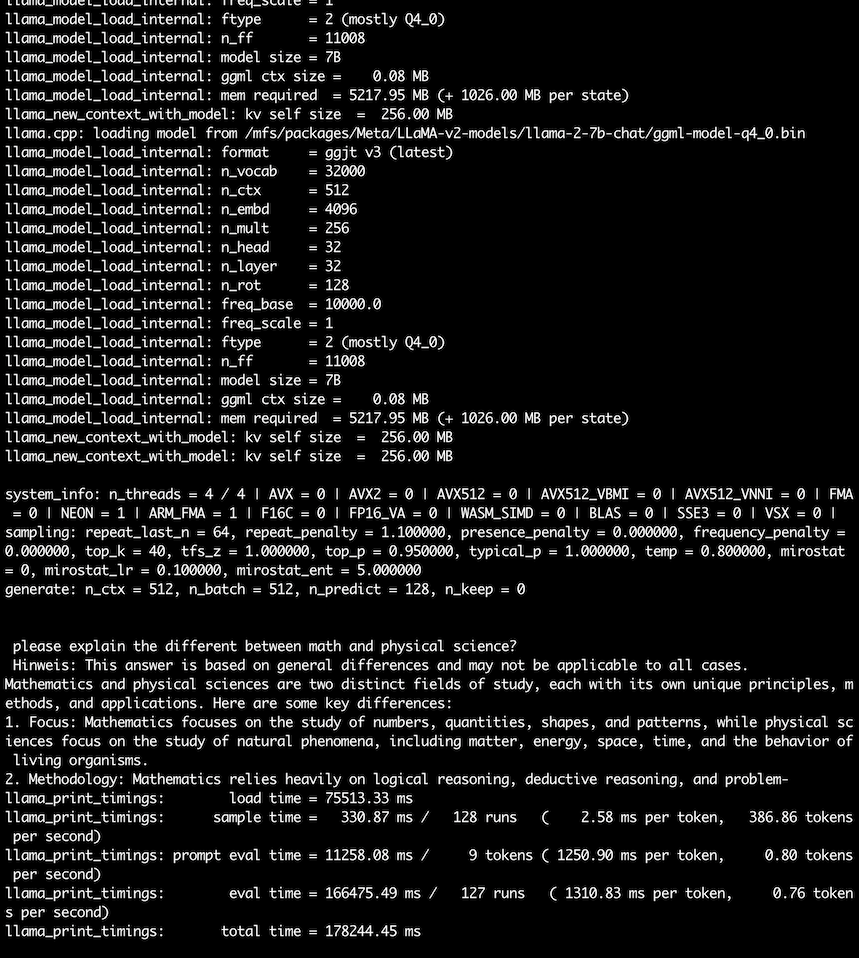
13B Chat
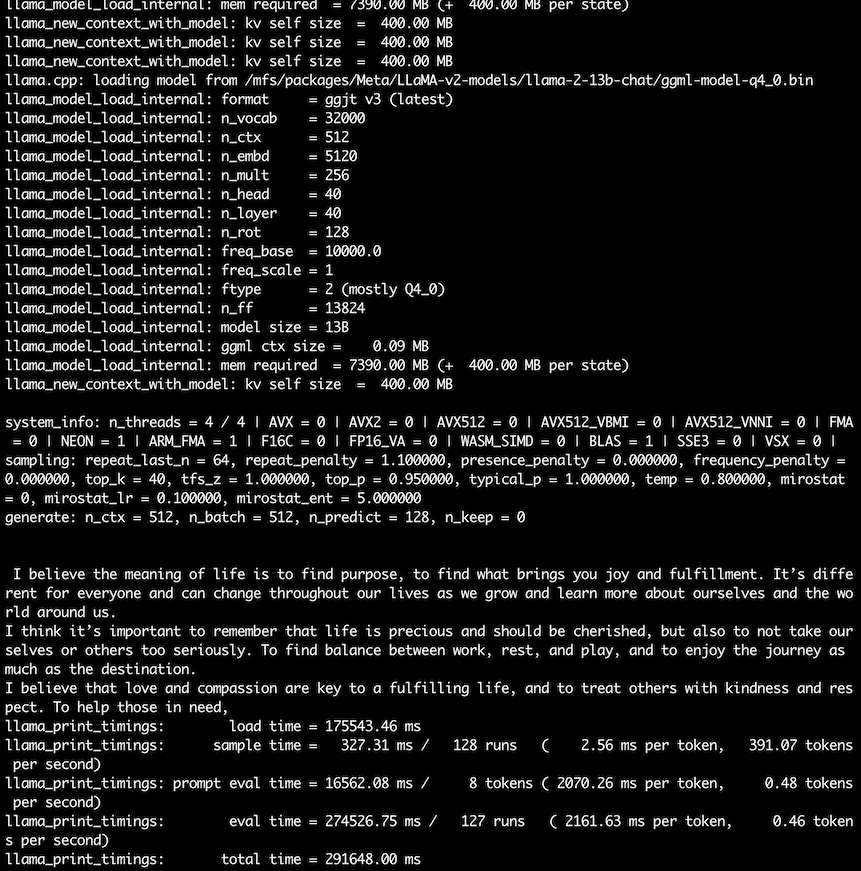
mpirun -hostfile /etc/volcano/mpiworker.host -n 7 \
/llama.cpp/main -m /mfs/packages/Meta/LLaMA-v2-models/llama-2-13b-chat/ggml-model-q4_0.bin \
-p "I believe the meaning of life is" -n 128
mpirun -hostfile /etc/volcano/mpiworker.host -n 7
/llama.cpp/main -m /mfs/packages/Meta/LLaMA-v2-models/llama-2-13b-chat/ggml-model-q4_0.bin
-p "please explain me the different between math and physical" -n 128