Horovod
之前写过一篇文章讨论如何使用TF2.0自带的分布式训练系统,在树莓派4上建立分布式训练集群。然而这里会有一个缺陷,我们需要在每一个节点上去启动写好的训练程式,等全部启动之后,整个分布式训练才会开始运作,那么能否通过MPI消息传递接口来完成分布式的训练,答案就在Uber开发的Horovod,MPI主要用在超算领域,在树莓上搭建MPI集群,第一个可以用来学习超算上的分布式计算,第二可以在实际中观察TF在ARMv8上进行分布式训练的性能。
回顾
horovod的开发可以从研究这篇论文开始Horovod: fast and easy distributed deep learning in Tensorflow
一般常见的分布式并行处理有两种,一种是数据并行,一种是模型并行,这个在之前的文章中讨论过,数据并行的优势是相对简单的。
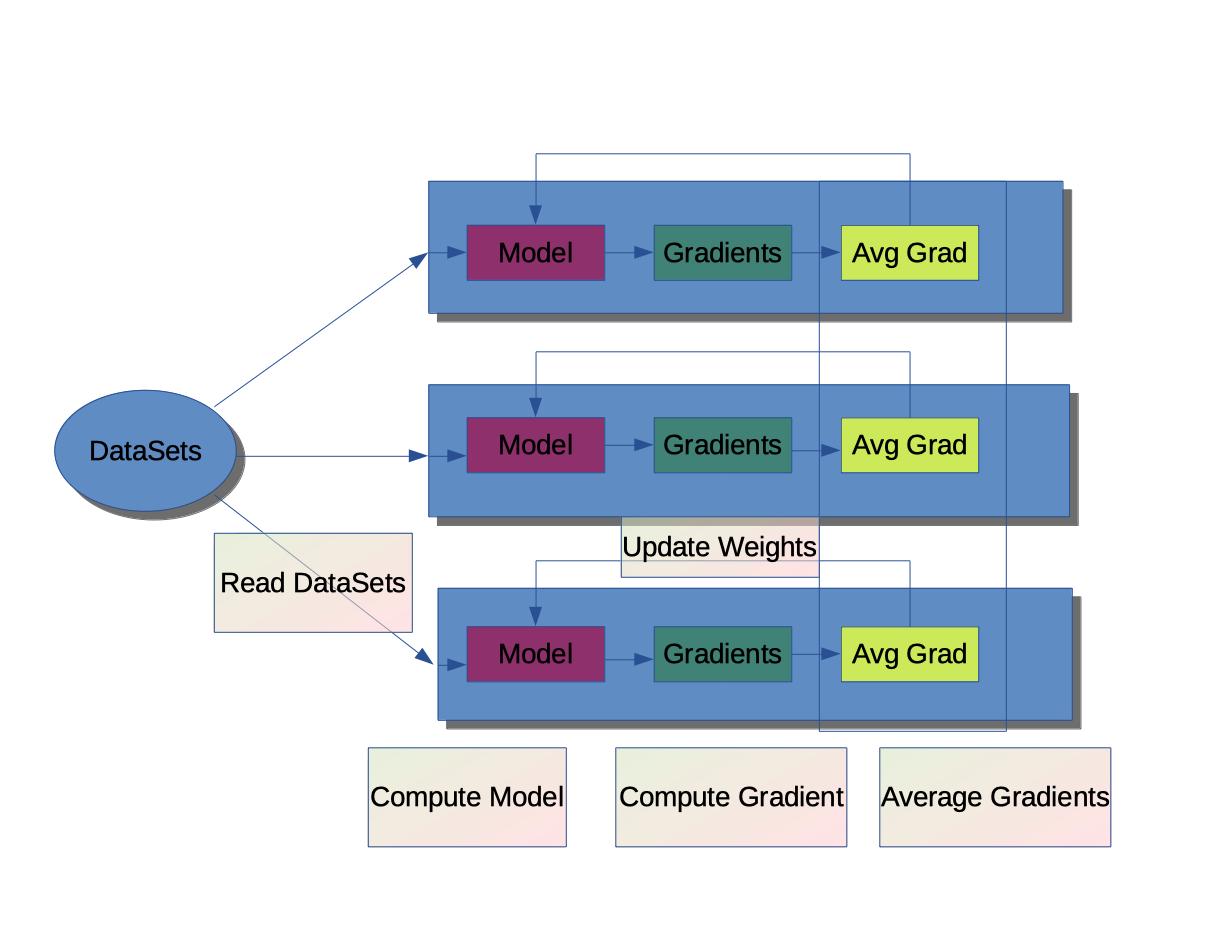
数据并行流程:
-
在每个节点上分发拷贝模型代码并运行
- 每个节点读取数据集开始训练
- 根据损失函数计算模型的梯度
-
合并每个节点所计算得到的梯度值,计算出新的平均梯度
-
根据计算得到的新梯度,更新每个节点上模型的参数和权重
-
重复上述过程
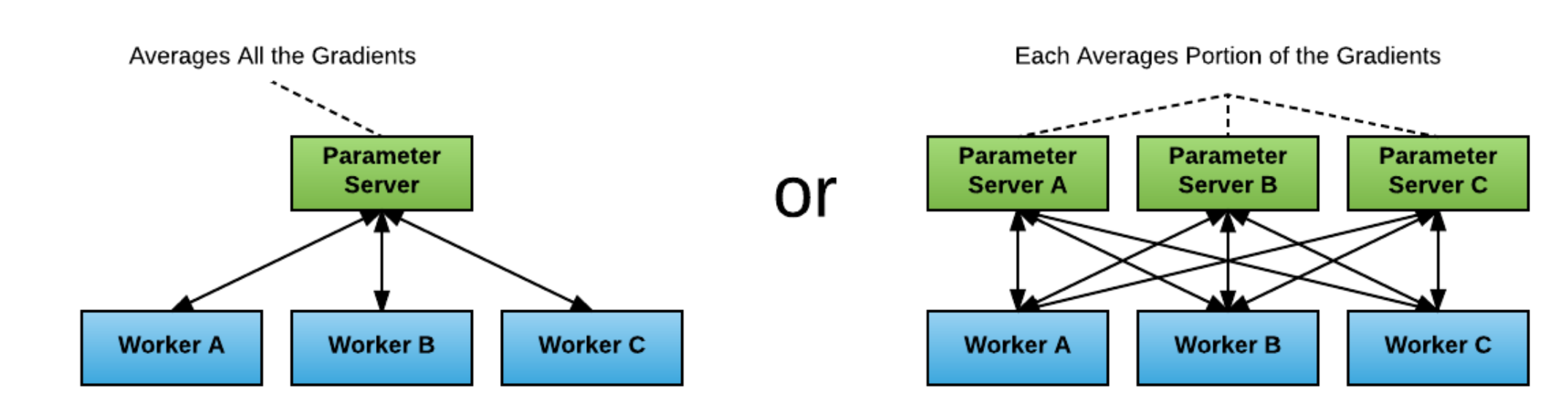
早期TF的分布式训练为PS架构,Worker训练模型,将获得的梯度发往parameter server,PS服务将收集到的数据进行均值化处理,开发人员需要在每台节点上启动Worker和PS,然后TF通过服务发现机制接入整个训练集群,这样就会出现两个瓶颈。
-
当只有一台PS服务时,会出现PS负载过高的情况
-
当有多台PS和多台Worker时,训练的瓶颈会出现在网络带宽层面
接下来就有了Ring-All-Reduce算法:
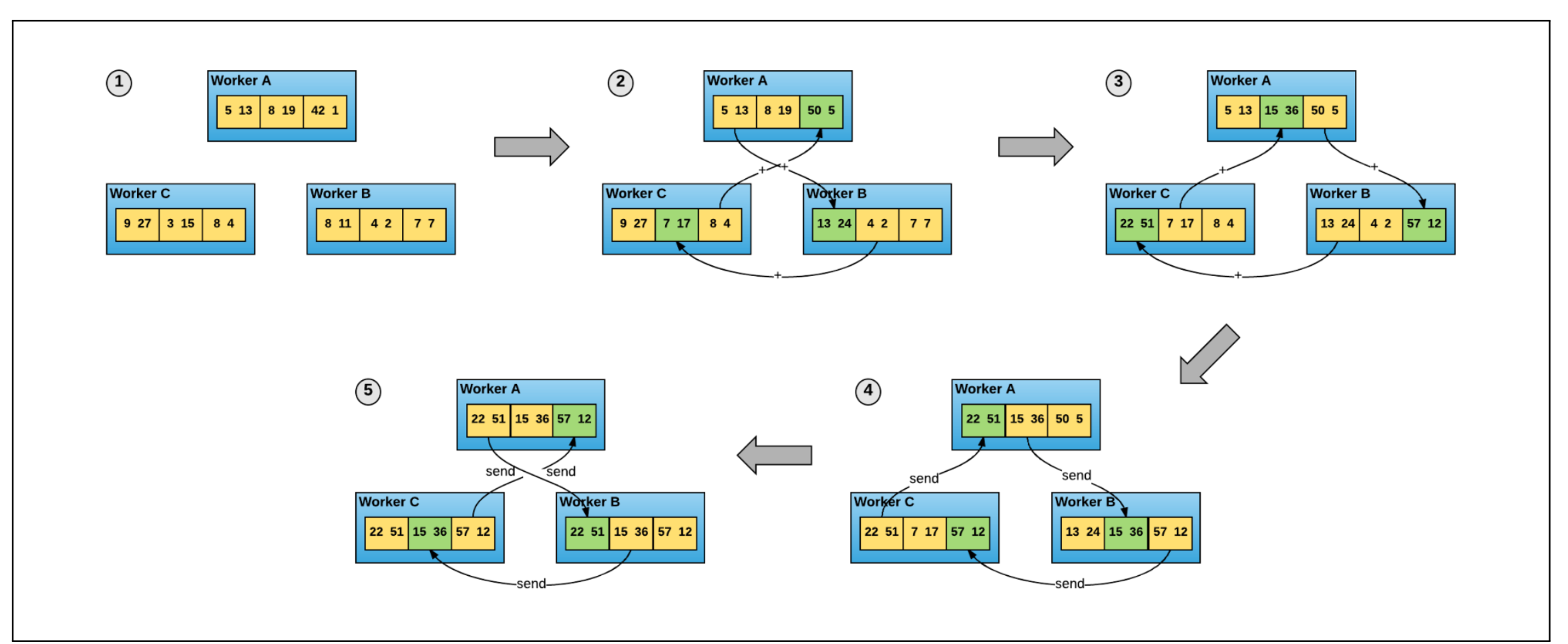
每个Worker节点连在一起形成闭环,通过以下算法将所有节点的梯度值的聚合存储在worker节点上: (->代表将数值传递到下一个worker节点,k代表数组号)

在MPI消息接口中,已经实现了AllReduce功能,MPICH MPI_Allreduce,程式中关于梯度的均值计算就只需要一个AllReduce()操作,然后再将得到的新梯度重新传递给每一个Worker。
使用horovod只需要在程式中增加horovod初始化和基于MPI的optimizer更新
论文中关于使用ring-allreduce和之前原版本TF性能利用率对比图:
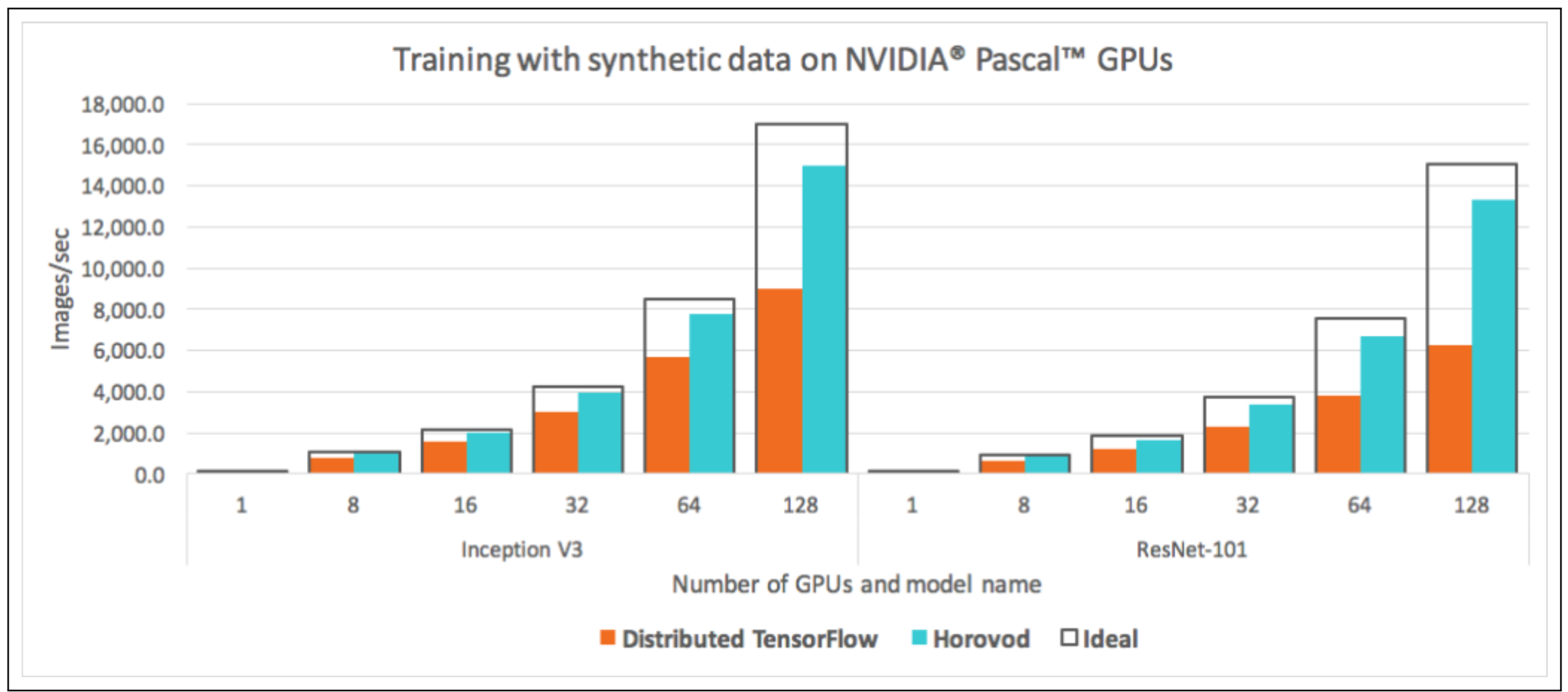
以下所有分布式训练均可在树莓派4集群上完成。
训练MNIST LeNet代码如下:
#!/bin/env python3
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
import numpy as np
import tensorflow as tf
from tensorflow import keras
import horovod.tensorflow.keras as hvd
hvd.init() // horovod 初始化
mnist = keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train,x_test = np.expand_dims(x_train, axis=3), np.expand_dims(x_test, axis=3)
model = keras.models.Sequential([
keras.layers.Conv2D(32, 3, padding='same', activation='relu',input_shape=(28,28,1)),
keras.layers.MaxPool2D(2),
keras.layers.Conv2D(64, 3, padding='same',activation='relu'),
keras.layers.MaxPool2D((2)),
keras.layers.Flatten(),
keras.layers.Dense(512, activation='relu'),
keras.layers.Dense(10, activation='softmax')])
opt = tf.optimizers.Adam(0.001 * hvd.size())
opt = hvd.DistributedOptimizer(opt) // 增加分布式的优化器
model.compile(optimizer=opt,loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
callbacks = [
hvd.callbacks.BroadcastGlobalVariablesCallback(0),
]
if hvd.rank() == 0:
callbacks.append(keras.callbacks.ModelCheckpoint('./checkpoint-{epoch}.h5'))
model.fit(x_train, y_train,steps_per_epoch=500,
callbacks=callbacks,
epochs=20,
verbose=1 if hvd.rank() == 0 else 0)
MPICH 版本
构建镜像 Dockerfile
FROM ubuntu:20.04
LABEL VERSION="1.0.0"
LABEL maintainer="[email protected]"
RUN apt-get -y update && apt-get -y upgrade
RUN apt-get install -y g++ gcc gfortran openssh-server build-essential make cmake pkg-config mpich libmpich-dev
RUN apt-get install libffi-dev libffi7 libblas-dev liblapack-dev libatlas-base-dev python3-numpy libhdf5-dev -y
RUN apt-get -y -q autoremove && apt-get -y -q clean
RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
RUN sed -i 's/#Port 22/Port 2222/' /etc/ssh/sshd_config
WORKDIR /
RUN mkdir /run/sshd -pv && mkdir /root/.ssh
RUN sed -i 's/#PermitRootLogin yes/PermitRootLogin yes/' /etc/ssh/sshd_config
RUN useradd -m -s /bin/bash -u 1001 chenfeng
RUN mkdir -pv /home/chenfeng/.ssh
COPY authorized_keys id_rsa.pub id_rsa /root/.ssh/
COPY authorized_keys id_rsa.pub id_rsa /home/chenfeng/.ssh/
RUN chown chenfeng:chenfeng /home/chenfeng/.ssh/authorized_keys
RUN chmod 0600 /root/.ssh/id_rsa && chmod 0600 /home/chenfeng/.ssh/id_rsa
COPY ./tensorflow-2.2.0-cp38-cp38-linux_aarch64.whl /tmp/
RUN pip3 install grpcio
RUN pip3 install scipy=="1.4.1"
RUN pip3 install /tmp/tensorflow-2.2.0-cp38-cp38-linux_aarch64.whl
RUN rm -fv /tmp/tensorflow-2.2.0-cp38-cp38-linux_aarch64.whl
RUN HOROVOD_WITH_TENSORFLOW=1 pip3 install horovod[tensorflow]
EXPOSE 2222
CMD ["/usr/sbin/sshd", "-D"]
OpenMPI 版本
构建镜像 Dockerfile
FROM ubuntu:20.04
LABEL VERSION="1.0.0"
LABEL maintainer="[email protected]"
RUN apt-get -y update && apt-get -y upgrade
RUN apt-get install -y g++ gcc gfortran openssh-server build-essential make cmake pkg-config
RUN apt-get install libffi-dev libffi7 libblas-dev liblapack-dev libatlas-base-dev python3-numpy libhdf5-dev libopenmpi-dev openmpi-bin -y
RUN apt-get -y -q autoremove && apt-get -y -q clean
RUN sed -i 's/PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
RUN sed -i 's/#Port 22/Port 2222/' /etc/ssh/sshd_config
WORKDIR /
RUN mkdir /run/sshd -pv && mkdir /root/.ssh
RUN sed -i 's/#PermitRootLogin yes/PermitRootLogin yes/' /etc/ssh/sshd_config
COPY ./ssh_config /etc/ssh/ssh_config
RUN useradd -m -s /bin/bash -u 1001 chenfeng
RUN mkdir -pv /home/chenfeng/.ssh
COPY authorized_keys id_rsa.pub id_rsa /root/.ssh/
COPY authorized_keys id_rsa.pub id_rsa /home/chenfeng/.ssh/
RUN chown chenfeng:chenfeng /home/chenfeng/.ssh/authorized_keys
RUN chmod 0600 /root/.ssh/id_rsa && chmod 0600 /home/chenfeng/.ssh/id_rsa
COPY ./tensorflow-2.2.0-cp38-cp38-linux_aarch64.whl /tmp/
RUN pip3 install grpcio
RUN pip3 install scipy=="1.4.1"
RUN pip3 install /tmp/tensorflow-2.2.0-cp38-cp38-linux_aarch64.whl
RUN rm -fv /tmp/tensorflow-2.2.0-cp38-cp38-linux_aarch64.whl
RUN HOROVOD_WITH_TENSORFLOW=1 pip3 install horovod[tensorflow]
RUN pip3 install ipython
RUN rm -fv /'=1.8.6'
EXPOSE 2222
CMD ["/usr/sbin/sshd", "-D"]
分布式训练程式测试
使用3 * Raspberry pi 4 4G 进行训练。
程式代码:
cat_vs_dog cnn-distributed.py:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Fri Jun 5 14:23:53 2020
@author: alexchen
"""
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
import tensorflow_datasets as tfds
import json
import os
import horovod.tensorflow.keras as hvd
hvd.init()
opt = tf.optimizers.Adam(0.001 * hvd.size())
opt = hvd.DistributedOptimizer(opt)
def create_model():
model = Sequential([
Conv2D(32,(3,3),input_shape=(64,64,3),activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Conv2D(32,(3,3),activation='relu'),
MaxPooling2D(pool_size=(2,2)),
Flatten(),
Dense(units=128,activation='relu'),
Dense(units=1, activation='sigmoid')
])
model.compile(optimizer=opt,loss='binary_crossentropy',metrics = ['accuracy'])
return model
dataset = tfds.load("cats_vs_dogs",
split=tfds.Split.TRAIN,
as_supervised=True,
data_dir="./tensorflow_datasets")
def resize(image, label):
image = tf.image.resize(image, [64, 64]) / 255.0
return image, label
callbacks = [
hvd.callbacks.BroadcastGlobalVariablesCallback(0),
]
if hvd.rank() == 0:
callbacks.append(keras.callbacks.ModelCheckpoint('./checkpoint-{epoch}.h5'))
batch_size = 32
multi_worker_dataset = dataset.repeat().map(resize).shuffle(1024).batch(batch_size)
model = create_model()
model.fit(multi_worker_dataset,
callbacks=callbacks,
steps_per_epoch = 50,
epochs = 50,
verbose=1 if hvd.rank() == 0 else 0)
horovodrun --verbose -np 3 --network-interface eth0 --hostfile ./hosts -p 2222 python3 cnn-distributed.py
最后的训练结果为:
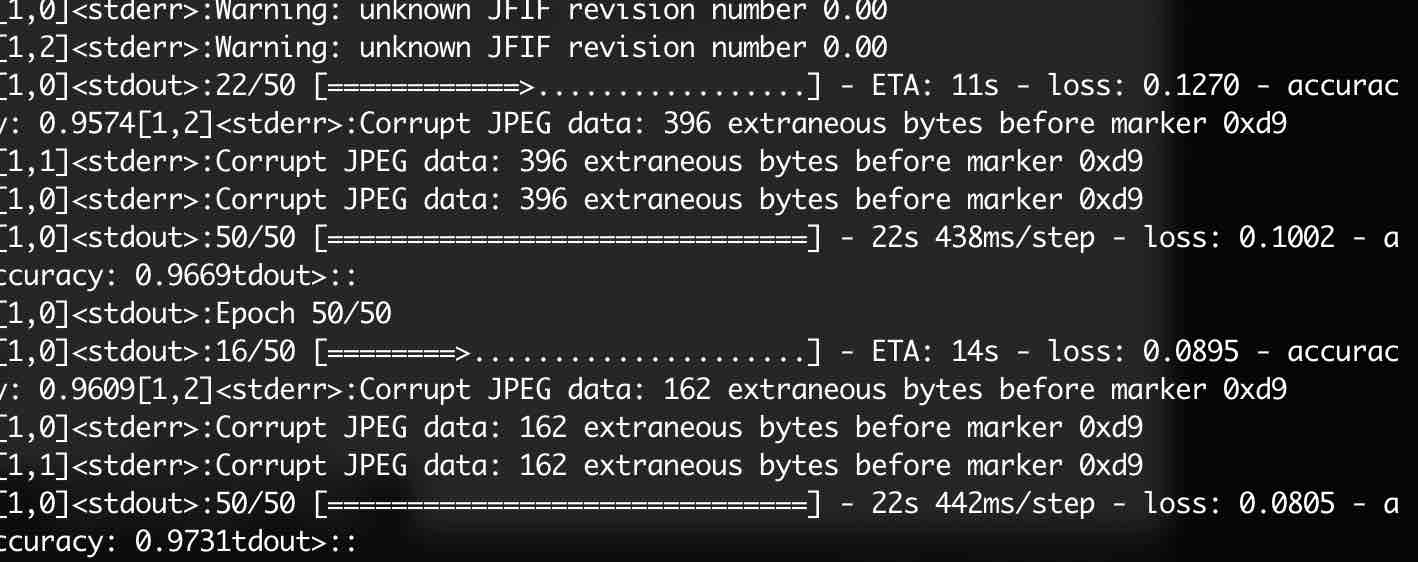
如果我们采用单台的训练模式:
horovodrun --verbose -np 1 python3 cnn-distributed.py
最后的结果为:
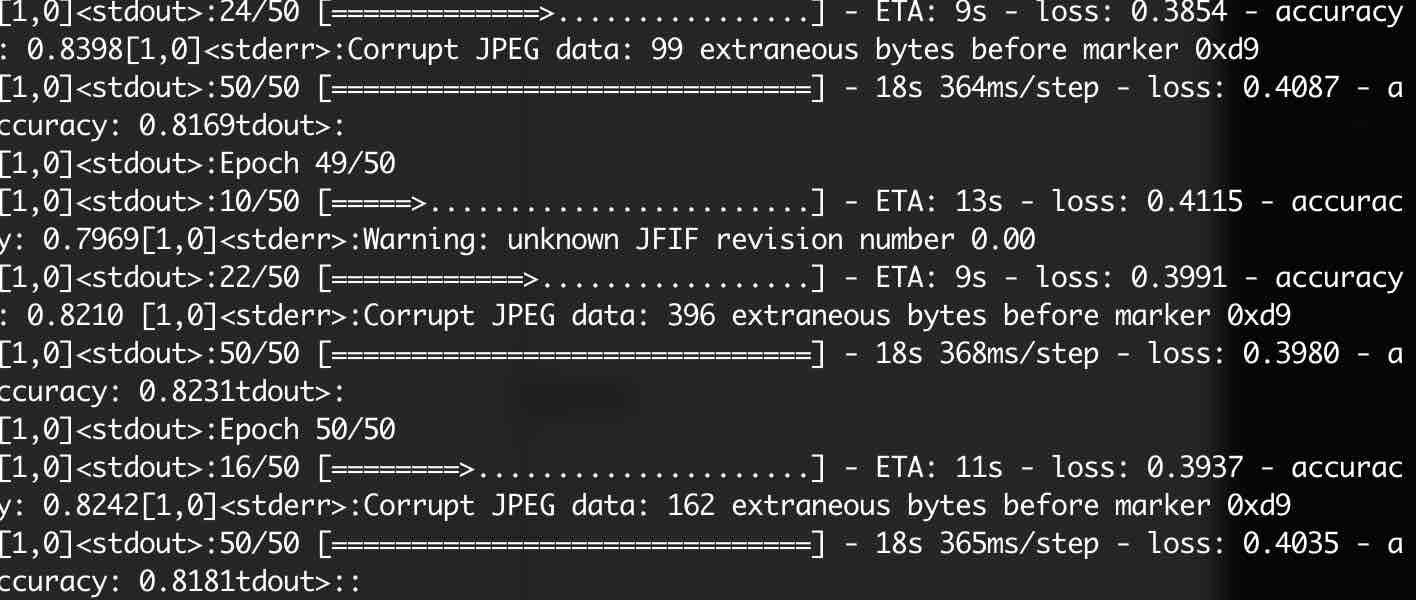
正确率分别为97%,82%,明显使用分布式训练时,模型的准确率能够更快的收敛,并且相较于单机训练多机训练时训练数据的吞吐量高于单机,后面我们会在根据肺部CT扫描图像判断该病人是否为Covid-19患者的模型中使用分布式训练。