动画程式代码如下:
lung-3D.nb
lung3d = AnatomyPlot3D[lung anatomical structure,
PlotTheme->"XRay"]
gif = {};
Do[
image = ImageResize[
Show[lung3d,
ViewPoint -> {3 Cos[x], 3 Sin[x], 0},
ViewAngle -> 20 Degree],
{256, 256}];
gif = Append[gif, image], {x, 0, 2 Pi, 0.1}]
Export["lung-3D.gif", gif, "AnimationRepetitions" -> Infinity ]
image = ImageResize[
Show[lung3d,
ViewPoint -> {3 Cos[Pi/2], 3 Sin[Pi/2], 0},
ViewAngle -> 20 Degree],
{512, 512}]
训练集收集
模型架构
本文我们会根据两个模型框架COVID-Net和VGG做为参考,构建能够在Raspberry pi 4上训练和部署的深度网络。
参考资料
模型
常用的图像模型架构:
-
MobileNet
-
DenseNet
-
Xception
-
ResNet
-
InceptionV3
-
InceptionResNetV2
-
VGGNet
-
NASNet
VGG16
模型架构

COVID-NET
模型架构
原型测试
VGG16 迁移学习
使用的数据集为covid19-radiography-database
NoteBook链接地址如下:
Mathematica VGG16 Transfer Learning Code
训练完模型之后,使用测试集来度量模型的正确率为94%。
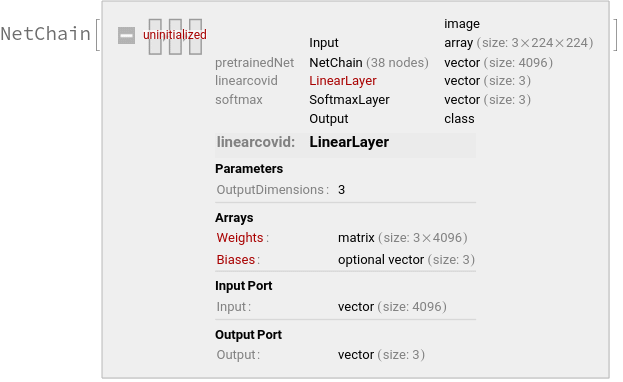
这里我们使用了迁移学习方法来加速模型的训练,将预先训练好的VGG16模型的顶层移除,添加三个分类的线性层,{“COVID-19”, “NORMAL”, “VIRAL”},只训练linearcovid这一层的参数。
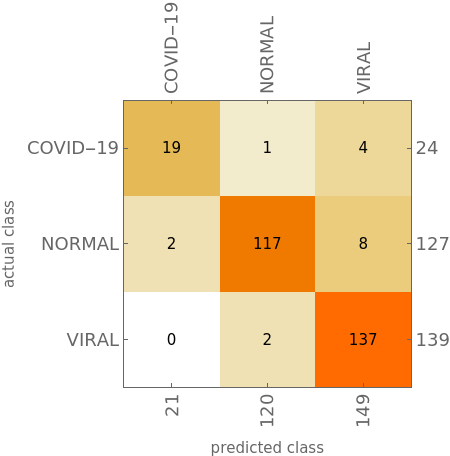
最后模型的ConfusionMatrixPlot:
在本次原型测试中,我们将VGG16用来对X-ray图像归类划分到三个子集中,分别为{“COVID-19”, “NORMAL”, “VIRAL”},数据集的图片总数为2905,Normal指正常人的肺部图片,VIRAL指其他的病毒感染的肺炎疾病图片。其中Covid-19只有219张,训练集,验证集,测试集占用划分为 8:1:1。
最后从互联网上随机获取到一张Covid-19病人的肺部X-Ray图像,在模型中验证:

得出的结果为COVID-19。
以上的测试结果正确率只是一个模糊的概念,因为我们的数据集只有2k。
增强版VGG16
上面使用了迁移学习技术,接下来我们需要探索的是,如何手动生成整个VGG16深度学习架构,将预先训练好的权重拷贝到我们自己所创建的VGG16网络中,然后采用分层训练的方法,训练某一个特征层,冻结其他特征层,同样我们也可以提供足够大的样本空间从头训练VGG16所有层的权重和偏差,以下所有原型代码均在mathematica中完成。
- Create VGG16 Model
vgg16Layers = Association[{
(* Block 1 *)
1 -> {
"features" -> 64,
"kernel" -> {3, 3},
"padding" -> 1,
"pooling" -> {
"kernel" -> {2, 2},
"stride" -> {2, 2}},
"layers" -> {"Conv1" ->
"Ramp1" -> "Conv2" -> "Ramp2" -> "Pooling"} },
(* Block 2 *)
2 -> {
"features" -> 128,
"kernel" -> {3, 3},
"padding" -> 1,
"pooling" -> {
"kernel" -> {2, 2},
"stride" -> {2, 2}},
"layers" -> {"Conv1" ->
"Ramp1" -> "Conv2" -> "Ramp2" -> "Pooling"}},
(* Block 3 *)
3 -> {
"features" -> 256,
"kernel" -> {3, 3},
"padding" -> 1,
"pooling" -> {
"kernel" -> {2, 2},
"stride" -> {2, 2}},
"layers" -> {"Conv1" ->
"Ramp1" ->
"Conv2" -> "Ramp2" -> "Conv3" -> "Ramp3" -> "Pooling"}},
(* Block 4 *)
4 -> {
"features" -> 512,
"kernel" -> {3, 3},
"padding" -> 1,
"pooling" -> {
"kernel" -> {2, 2},
"stride" -> {2, 2}},
"layers" -> {"Conv1" ->
"Ramp1" ->
"Conv2" -> "Ramp2" -> "Conv3" -> "Ramp3" -> "Pooling"}},
(* Block 5 *)
5 -> {
"features" -> 512,
"kernel" -> {3, 3},
"padding" -> 1,
"pooling" -> {
"kernel" -> {2, 2},
"stride" -> {2, 2}},
"layers" ->
{"Conv1" ->
"Ramp1" ->
"Conv2" -> "Ramp2" -> "Conv3" -> "Ramp3" -> "Pooling"}}
}];
整个 VGG16 重点在卷积层上,架构如上述代码,结构表述如下:
特征层 n -> {“features” -> 输出特征数, “kernel” -> 卷积核大小, “padding” -> 填充大小,“pooling” -> {“kernel” -> 池化层核, “stride” -> 池化层步长, “layers” -> 该特征层连接结构}}
卷积层总共有分5个模块,每个卷积层的卷积核均为{3,3},移动步长为{1,1},填充为{{1,1},{1,1}},填充可以理解为开始和结束的位置偏移,比如我们输入的是一张两维图片,我们可以理解padding为{{x_begin, x_end}, {y_begin, y_end}}。
生成 VGG16 模型:
(* 该函数采用尾递归方式解析我们上面的VGG16模型树,并生成层结构列表 *)
reMapLayers[layers_, return_, blockInfo_] := Module[{key, values, res},
If[MatchQ[layers, KeyValuePattern[_ -> _]],
key = Keys[layers][[1]];
values = Values[layers];
If[StringContainsQ[key, "conv", IgnoreCase -> True],
res =
Append[return, key -> ConvolutionLayer @@ blockInfo["conv2"]],
If[StringContainsQ[key, "ramp", IgnoreCase -> True],
res = Append[return, key -> ElementwiseLayer["ReLU"]],
If[StringContainsQ[key, "pool", IgnoreCase -> True],
res = Append[return, key -> PoolingLayer @@ blockInfo["pooling"]]
]]],
If[StringContainsQ[layers[[1]], "pool", IgnoreCase -> True],
res =
Append[return,
layers[[1]] -> PoolingLayer @@ blockInfo["pooling"]];
Return[res]]];
reMapLayers[values, res, blockInfo]]
(* 该函数通过调用reMapLayers来生成每一个Block的模型层 *)
vgg16Unit[nBlock_] := Module[{conv2, pooling, blockinfo, layers},
conv2 = {"features", "kernel", PaddingSize -> "padding"} /.
vgg16Layers[nBlock];
pooling = {"kernel", "stride"} /. (
"pooling" /. vgg16Layers[nBlock] );
blockinfo = <|"conv2" -> conv2, "pooling" -> pooling|>;
layers = "layers" /. vgg16Layers[nBlock];
NetChain[reMapLayers[layers, {}, blockinfo]]
]
(* 结合上面提供的函数,createVGG16Model 用来生成最终的VGG16模型,调用方式:
vgg16net =
createVGG16Model[input -> {224, 224, 3}, output -> {"cat", "dog"},
transferLearning -> True]
input: 输入的图像维度,(H * W * Channels)
output: 数据的对应标签
transferLearning -> True: 表示该模型采用迁移学习技术,新生成模型的权重会复用已经训练好的VGG16模型的权重
*)
Options[createVGG16Model] = {input -> {224, 224, 3},
output -> {"cat", "dog"}, transferLearning -> False};
createVGG16Model[OptionsPattern[]] :=
Module[{blocks, topLayers, net, lossnet, trainedNet, dims, channels,
extractConvInfo, preModel, nchannels, conv1weights, conv1biases,
combinRGBToGray,
input = OptionValue[input],
output = OptionValue[output],
transferLearning = OptionValue[transferLearning]},
(* preTrained Model Import *)
preModel :=
NetModel["VGG-16 Trained on ImageNet Competition Data"];
(* conver RGB Channel conv1 to Grayscale conv1 *)
combinRGBToGray[rgbC_] := Module[{r, g, b, gray},
r = rgbC[[1]];
g = rgbC[[2]];
b = rgbC[[3]];
gray = 0.2989 r + 0.5870 g + 0.1140 b;
{gray}];
(* extract preTrained Model Weights and Biases *)
extractConvInfo[preTrainedmodel_] :=
Module[{data = {}, keys, allInfo},
allInfo = NetExtract[preTrainedmodel, All];
keys =
Select[Keys[allInfo],
StringContainsQ[#, "conv", IgnoreCase -> True] &];
# -> allInfo[#] & /@ keys];
(* Set dims and channels, input and output *)
dims = input[[1 ;; 2]];
nchannels = input[[3]];
channels = If[nchannels == 3, "RGB", "Grayscale"];
trainedNet =
If[transferLearning, Association[extractConvInfo[preModel]],
None];
input = NetEncoder[{"Image", dims, ColorSpace -> channels}];
output = NetDecoder[{"Class", output}];
(* top layers *)
topLayers = NetChain[{
"fc0" -> FlattenLayer[],
"fc1" -> LinearLayer[4096],
"ramp1" -> Ramp,
"drop1" -> DropoutLayer[],
"fc2" -> LinearLayer[4096],
"ramp2" -> Ramp,
"drop2" -> DropoutLayer[],
"fc4" -> LinearLayer[],
"soft" -> SoftmaxLayer[]
}];
(* VGG16 Blocks *)
blocks = <|
"arg" -> ImageAugmentationLayer[dims],
"block1" -> vgg16Unit[1],
"block2" -> vgg16Unit[2],
"block3" -> vgg16Unit[3],
"block4" -> vgg16Unit[4],
"block5" -> vgg16Unit[5],
"top" -> topLayers
|>;
net = NetGraph[
blocks,
{"arg" ->
"block1" ->
"block2" -> "block3" -> "block4" -> "block5" -> "top"},
"Input" -> input,
"Output" -> output];
If[transferLearning,
If[Join[dims, {nchannels}] == {224, 224, 3},
net =
NetReplacePart[net, {"block1", "Conv1"} -> trainedNet["conv1_1"]],
If[Join[dims, {nchannels}] == {224, 224, 1},
conv1weights = NetExtract[trainedNet["conv1_1"], "Weights"];
conv1biases = NetExtract[trainedNet["conv1_1"], "Biases"];
conv1weights =
NumericArray@Map[combinRGBToGray, Normal[conv1weights]];
net =
NetReplacePart[
net, {"block1", "Conv1", "Weights"} -> conv1weights];
net =
NetReplacePart[
net, {"block1", "Conv1", "Biases"} -> conv1biases]]];
net = NetReplacePart[
net, {"block1", "Conv2"} -> trainedNet["conv1_2"]];
net = NetReplacePart[
net, {"block2", "Conv1"} -> trainedNet["conv2_1"]];
net = NetReplacePart[
net, {"block2", "Conv2"} -> trainedNet["conv2_2"]];
net = NetReplacePart[
net, {"block3", "Conv1"} -> trainedNet["conv3_1"]];
net = NetReplacePart[
net, {"block3", "Conv2"} -> trainedNet["conv3_2"]];
net = NetReplacePart[
net, {"block3", "Conv3"} -> trainedNet["conv3_3"]];
net = NetReplacePart[
net, {"block4", "Conv1"} -> trainedNet["conv4_1"]];
net = NetReplacePart[
net, {"block4", "Conv2"} -> trainedNet["conv4_2"]];
net = NetReplacePart[
net, {"block4", "Conv3"} -> trainedNet["conv4_3"]];
net = NetReplacePart[
net, {"block5", "Conv1"} -> trainedNet["conv5_1"]];
net = NetReplacePart[
net, {"block5", "Conv2"} -> trainedNet["conv5_2"]];
net = NetReplacePart[
net, {"block5", "Conv3"} -> trainedNet["conv5_3"]];
net,
net]]
最后我们尝试采用新生成的模型,迁移学习catVSdog,测试我们的模型是否能正常工作。
Options[createVGG16Model]
{input -> {224, 224, 3}, output -> {"cat", "dog"},
transferLearning -> False}
vgg16net =
createVGG16Model[input -> {224, 224, 3}, output -> {"cat", "dog"},
transferLearning -> True]

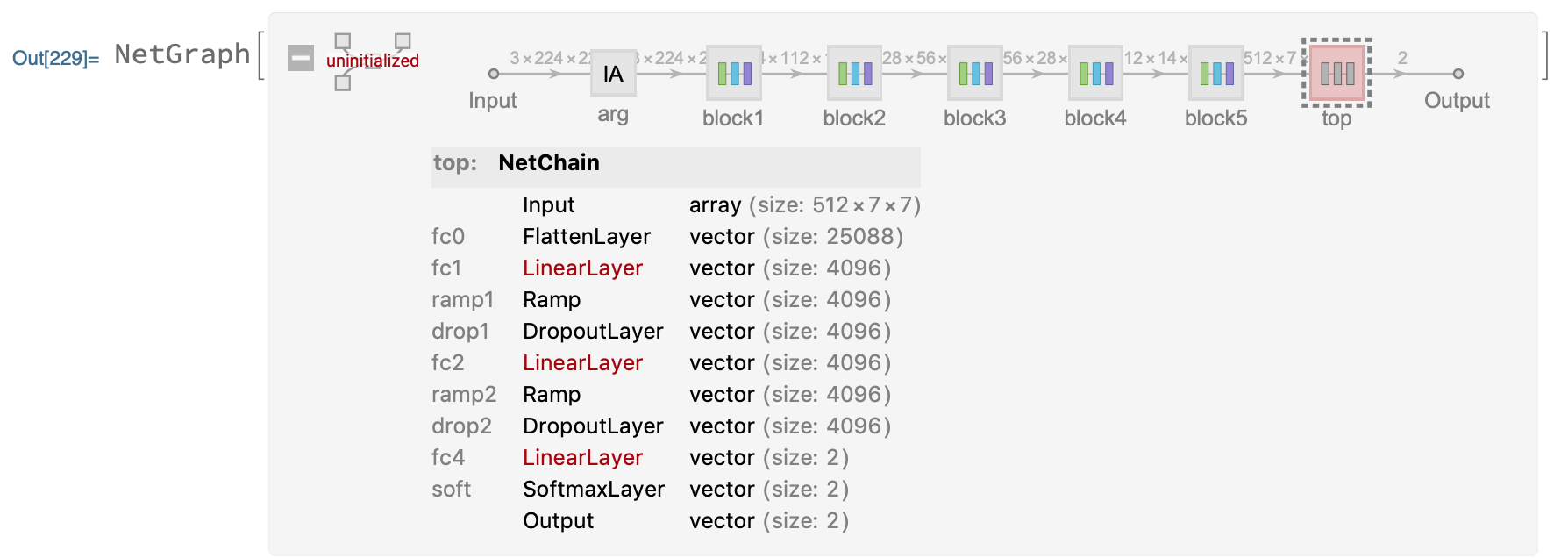
模型的结构如上图所示,总共分为6个模块,{block1,block2,block3,block4,block5,top},其中block{1~5}卷积层的权重和偏差已经被设定,top层的权重和偏差没有被初始化,这一层的参数是我们需要训练的,最后的分类为{‘cat’, ‘dog’}。
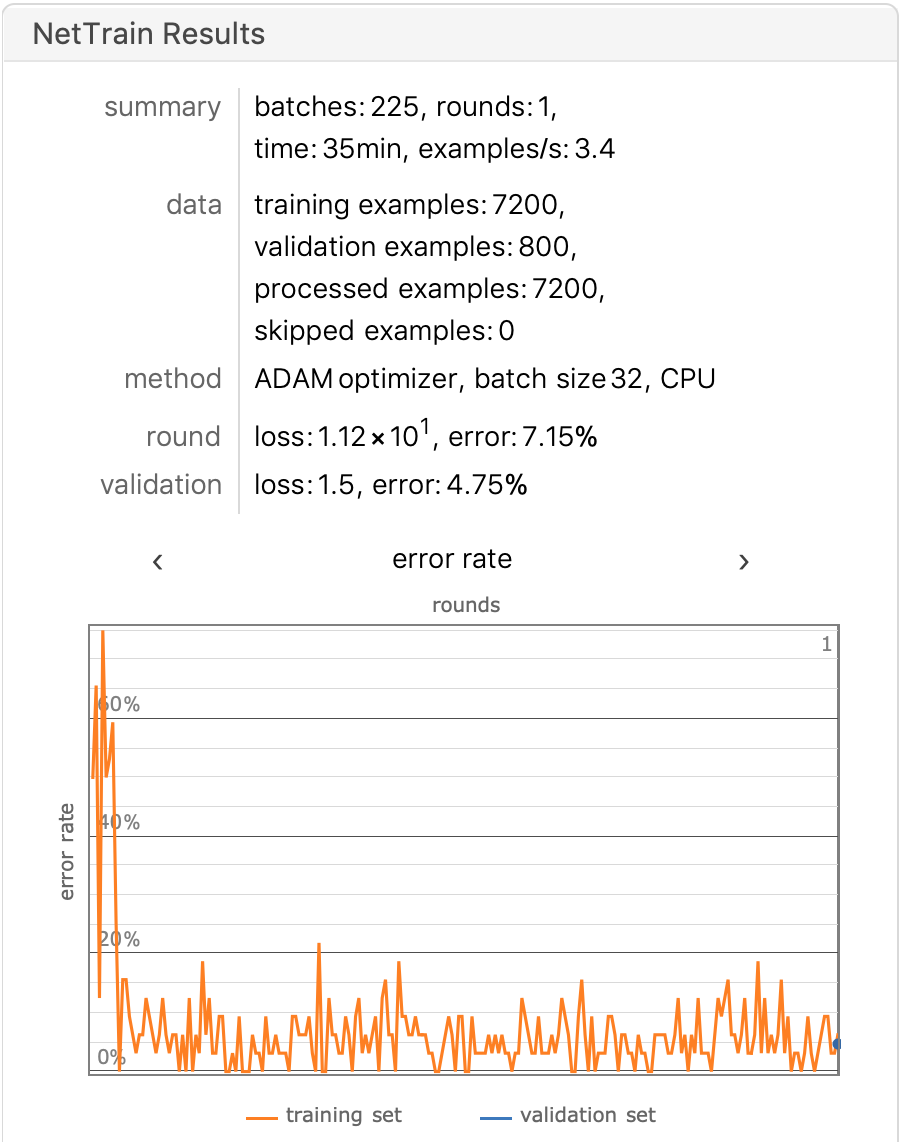
只训练一轮,我们来测试下模型的准确率如何:
LearningRateMultipliers -> {“block” -> 0} 用于冻结block层的权重
trainedVgg16 =
NetTrain[vgg16net, traingDataFilesSplit, All,
ValidationSet -> validDataFilesSplit,
TrainingProgressReporting -> "Panel", BatchSize -> 32,
LearningRateMultipliers -> {"block1" -> 0, "block2" -> 0,
"block3" -> 0, "block4" -> 0, "block5" -> 0, _ -> 1},
MaxTrainingRounds -> 1
]
训练结果如下:
使用测试集来观察模型的准确率:
NetMeasurements[trainedVgg16["TrainedNet"], testDataFiles, "Accuracy"]
0.954
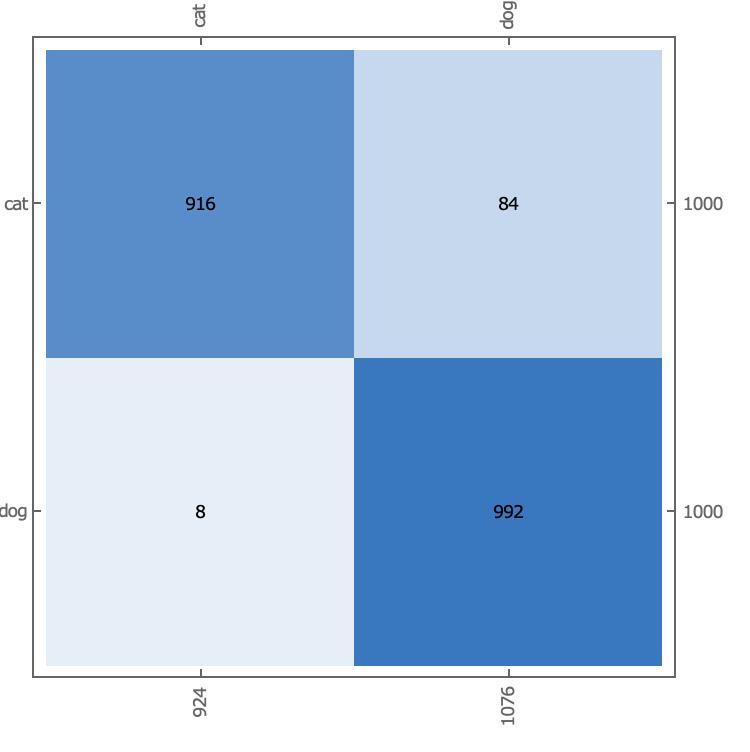
有84张cat实际被误认为是dog。
确认冻结层是否在训练过程中确实是冻结状态:
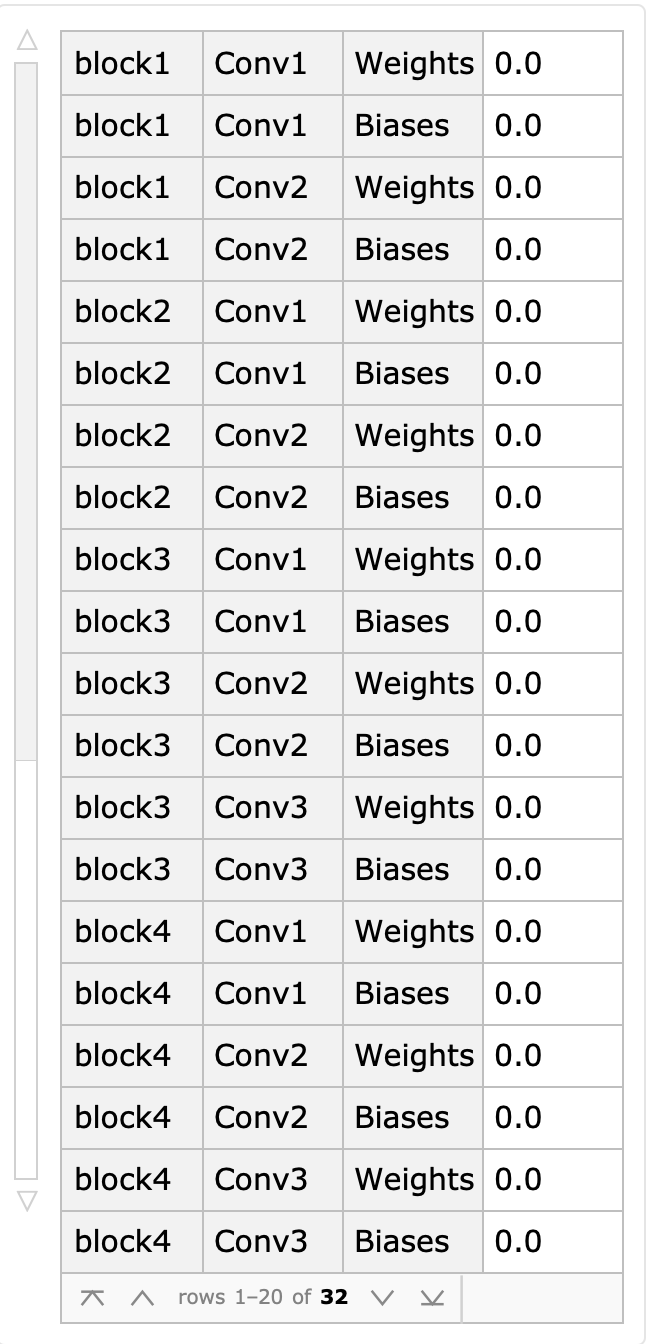
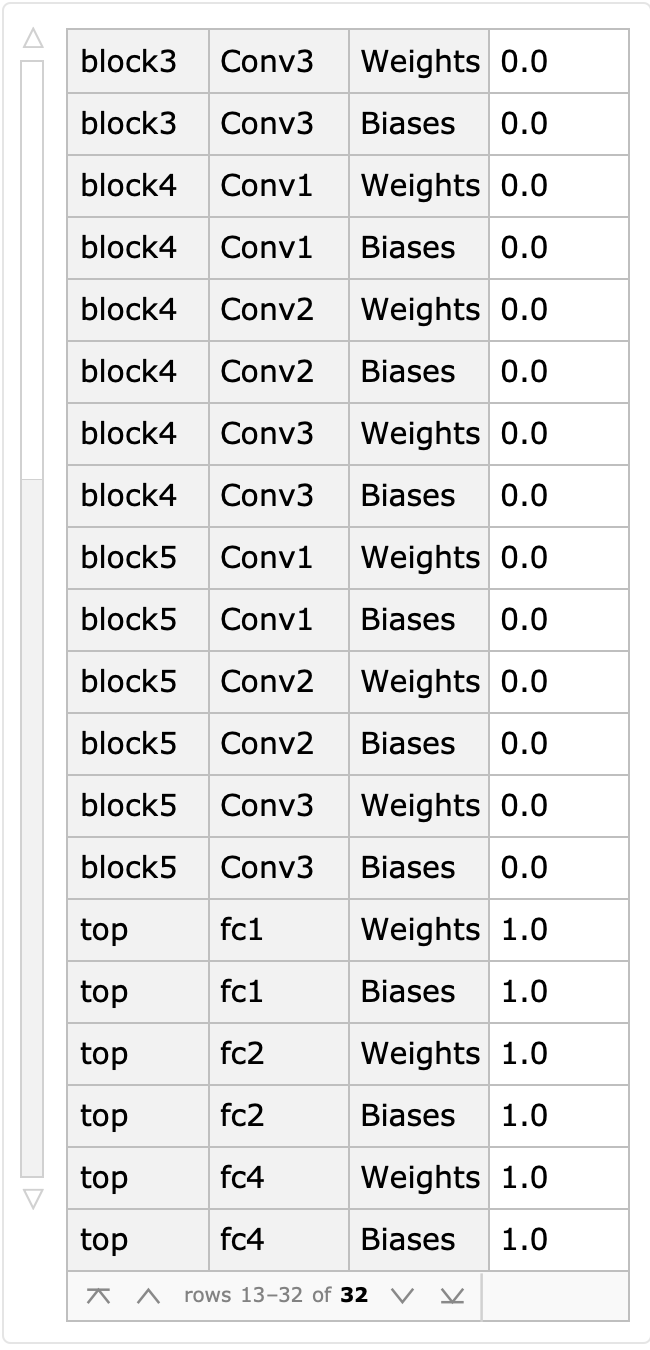
可以确定学习率对于所有的Block层都是0,只有top层是1。
那么还有没有可以改进的方式继续提高模型的正确率?
参考一篇论文Covid-19 detection using CNN transfer learning from X-ray Images
论文中使用如下CNN架构
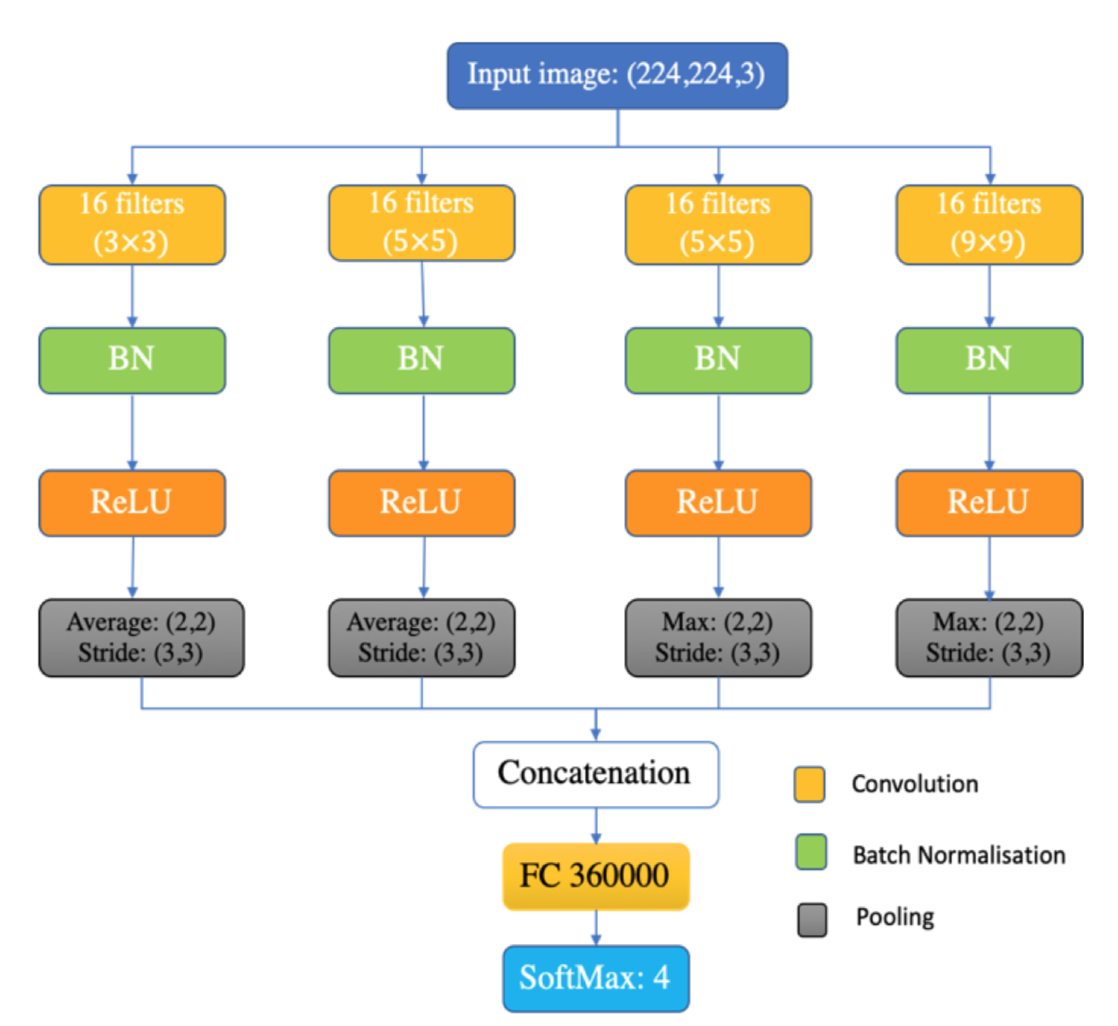
XConvidNet = NetInitialize[NetGraph[<|
"concat" -> CatenateLayer[],
"conv1" -> ConvolutionLayer[16, 3, PaddingSize -> 1],
"bn1" -> BatchNormalizationLayer[],
"relu1" -> Ramp,
"pooling1" -> PoolingLayer[{2, 2}, {3, 3}],
"conv2" -> ConvolutionLayer[16, 5, PaddingSize -> 2],
"bn2" -> BatchNormalizationLayer[],
"relu2" -> Ramp,
"pooling2" -> PoolingLayer[{2, 2}, {3, 3}],
"conv3" -> ConvolutionLayer[16, 5, PaddingSize -> 2],
"bn3" -> BatchNormalizationLayer[],
"relu3" -> Ramp,
"pooling3" -> PoolingLayer[{2, 2}, {3, 3}],
"conv4" -> ConvolutionLayer[16, 9, PaddingSize -> 5],
"bn4" -> BatchNormalizationLayer[],
"relu4" -> Ramp,
"pooling4" -> PoolingLayer[{2, 2}, {3, 3}],
"fc" -> FlattenLayer[],
"linear0" -> LinearLayer[],
"Soft" -> SoftmaxLayer[]
|>, {
"conv1" -> "bn1" -> "relu1" -> "pooling1" -> "concat",
"conv2" -> "bn2" -> "relu2" -> "pooling2" -> "concat",
"conv3" -> "bn3" -> "relu3" -> "pooling3" -> "concat",
"conv4" -> "bn4" -> "relu4" -> "pooling4" -> "concat",
"concat" -> "fc" -> "linear0" -> "Soft"},
"Input" -> NetEncoder[{"Image", {224, 224}, ColorSpace -> "RGB"}],
"Output" -> NetDecoder[{"Class", {"cat", "dog"}}]]]
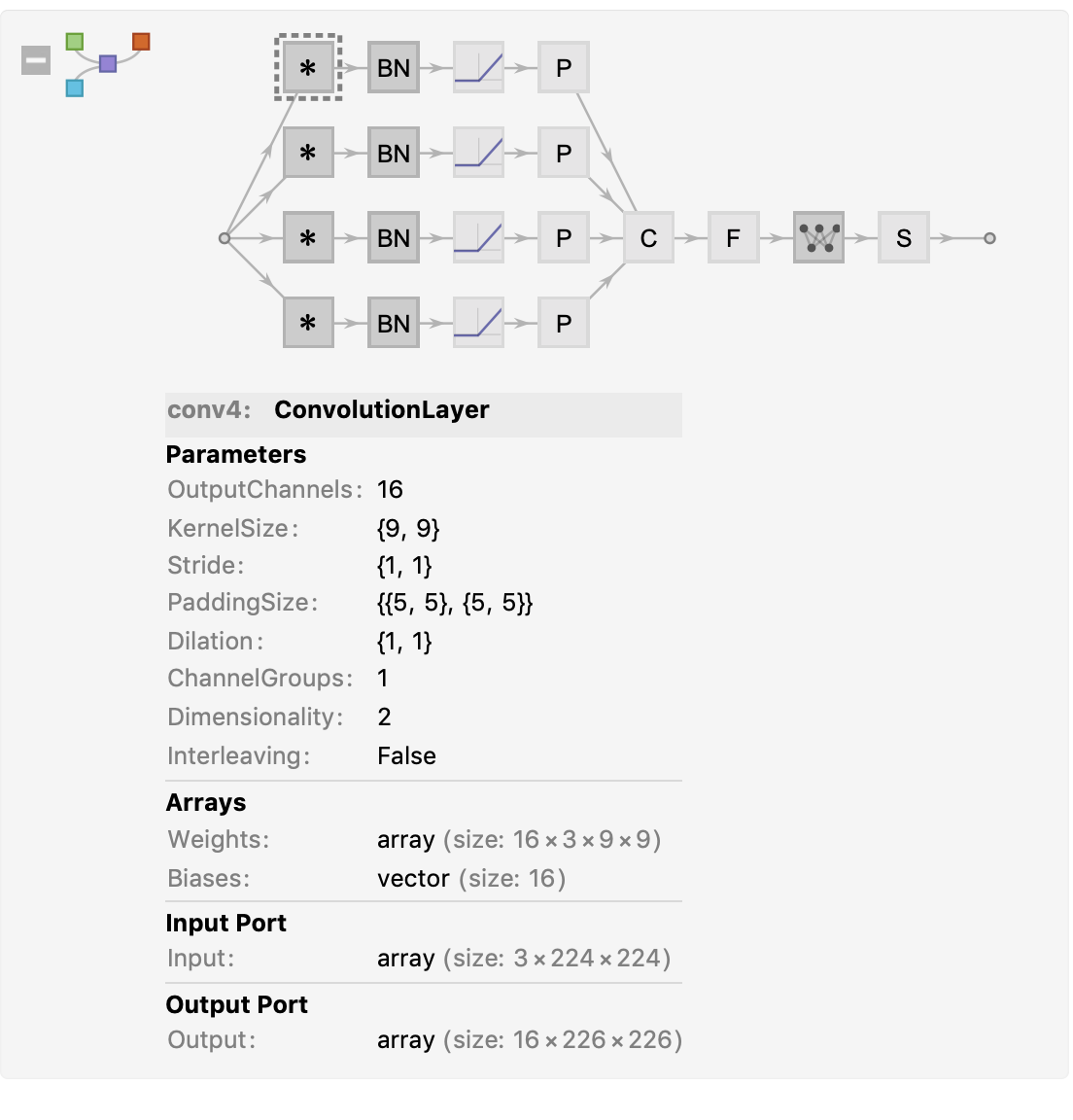
这样就启发我们是否可以采用同样的方式将两种或者多种CNN模型结合在一起,扩展特征的域,通过迁移学习的方式,将多个CNN的模型最后输出的特征连接到同一个张量中,最后对该张量进行Flatten操作,我们只需要要训练"fc"->“linear0"的参数即可。
接下来我们结合Resnet-50和VGG16来试验我们的上述架构,生成Resnet-50模型架构并且将预先训练好的Resnet50权重复制模型中,如同创建VGG16模型,这里我们先直接使用Wolfram Neural Network预先训练好的ResNet50。
newNet = NetGraph[<|
"arg" ->
ImageAugmentationLayer[{224, 224},
"ReflectionProbabilities" -> {0.5, 0.5}],
"resNet" -> NetTake[resNet, {"conv1", "5c"}] ,
"vgg" -> NetTake[vgg16net, {"block1", "block5"}],
"concat" -> CatenateLayer[],
"pooling" -> PoolingLayer[{7, 7}, "Function" -> Mean],
"fc0" -> FlattenLayer[],
"fc1" -> LinearLayer[500],
"fc2" -> LinearLayer[2],
"soft" -> SoftmaxLayer[]|>,
{NetPort["Input"] -> "arg" -> {"resNet", "vgg"},
{"resNet", "vgg"} ->
"concat" -> "pooling" -> "fc0" -> "fc1" -> "fc2" -> "soft"},
"Input" -> NetEncoder[{"Image", {224, 224}, ColorSpace -> "RGB"}],
"Output" -> NetDecoder[{"Class", {"cat", "dog"}}]]
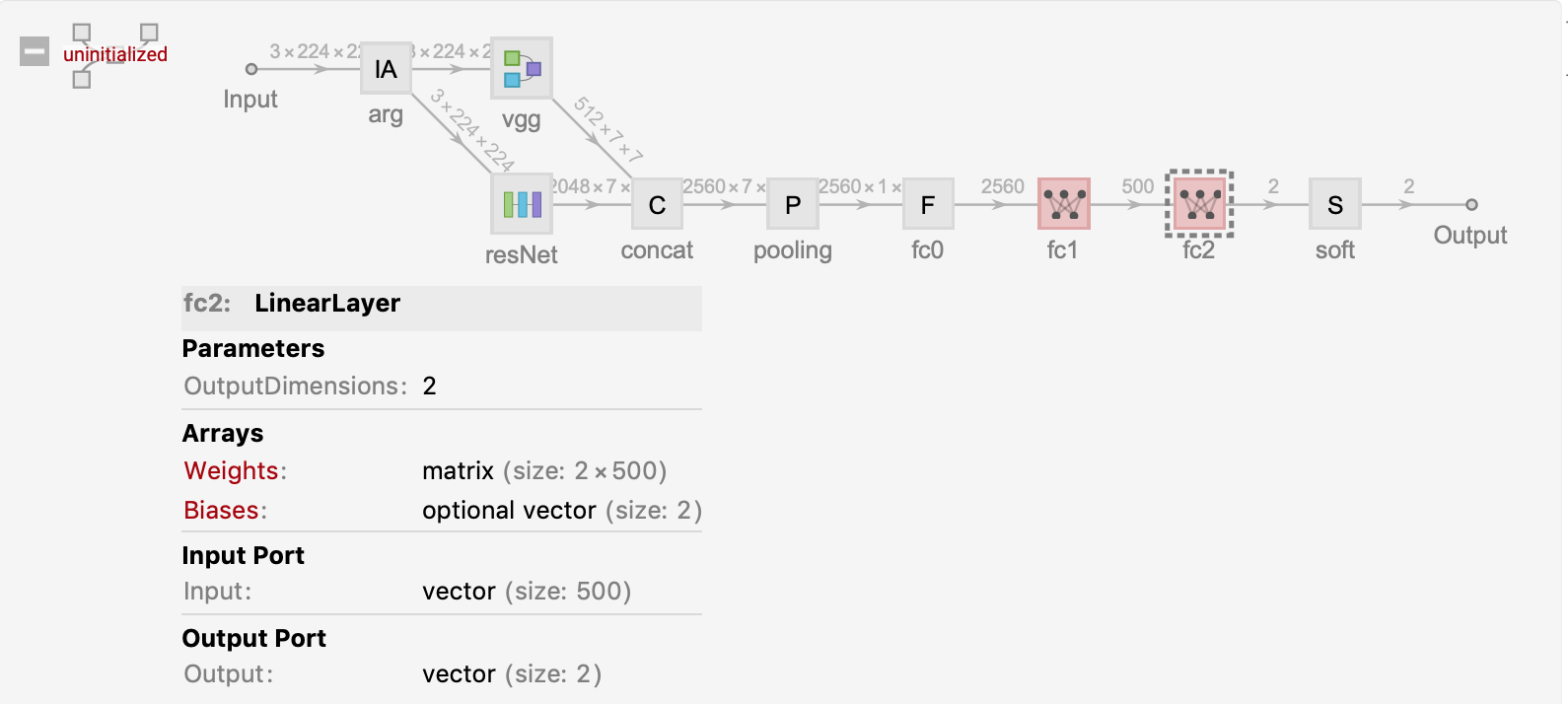
我们只需要训练fc1 fc2 这两个线性层的参数,固定其他层的权重,训练过程和训练结果如下,为了节省时间,并没有训练完整个epoch,只训练半个小时,然后我们与上述VGG16训练结果对比。
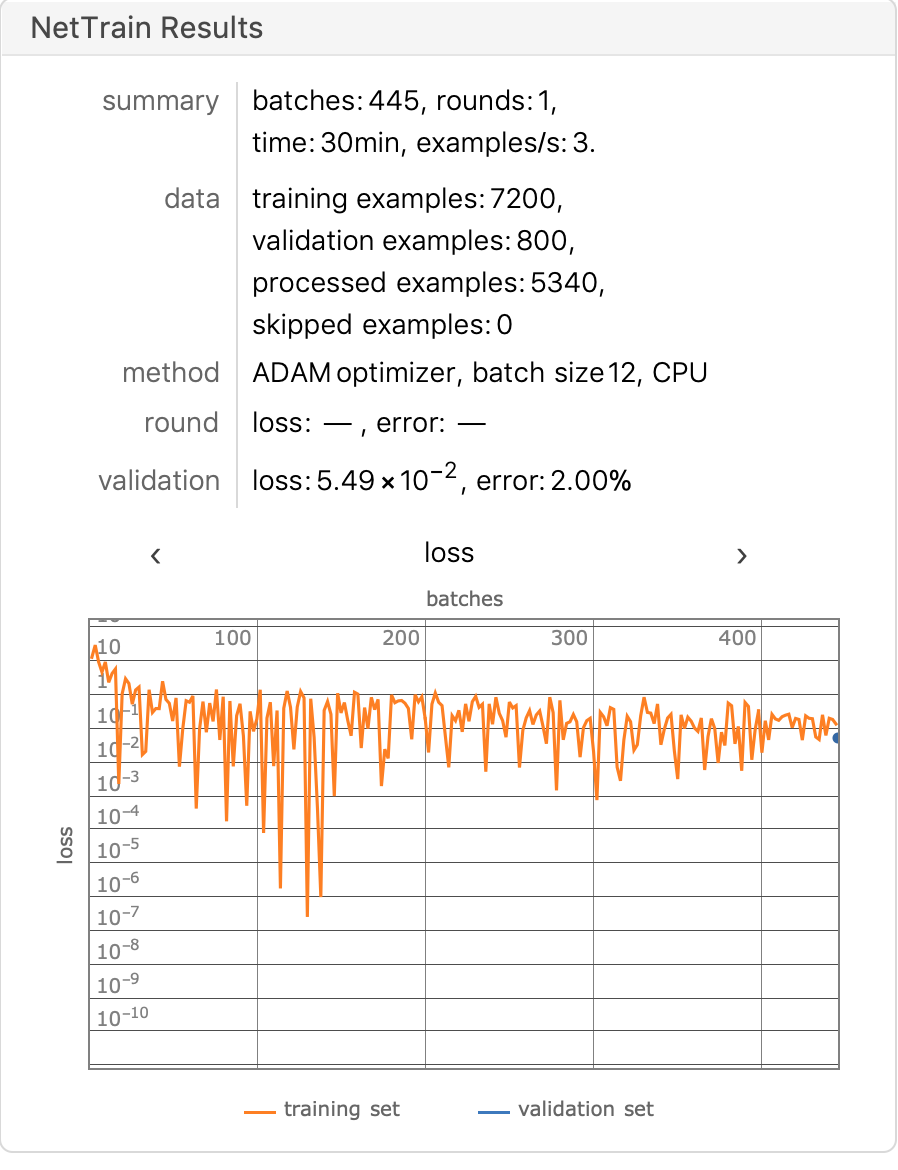
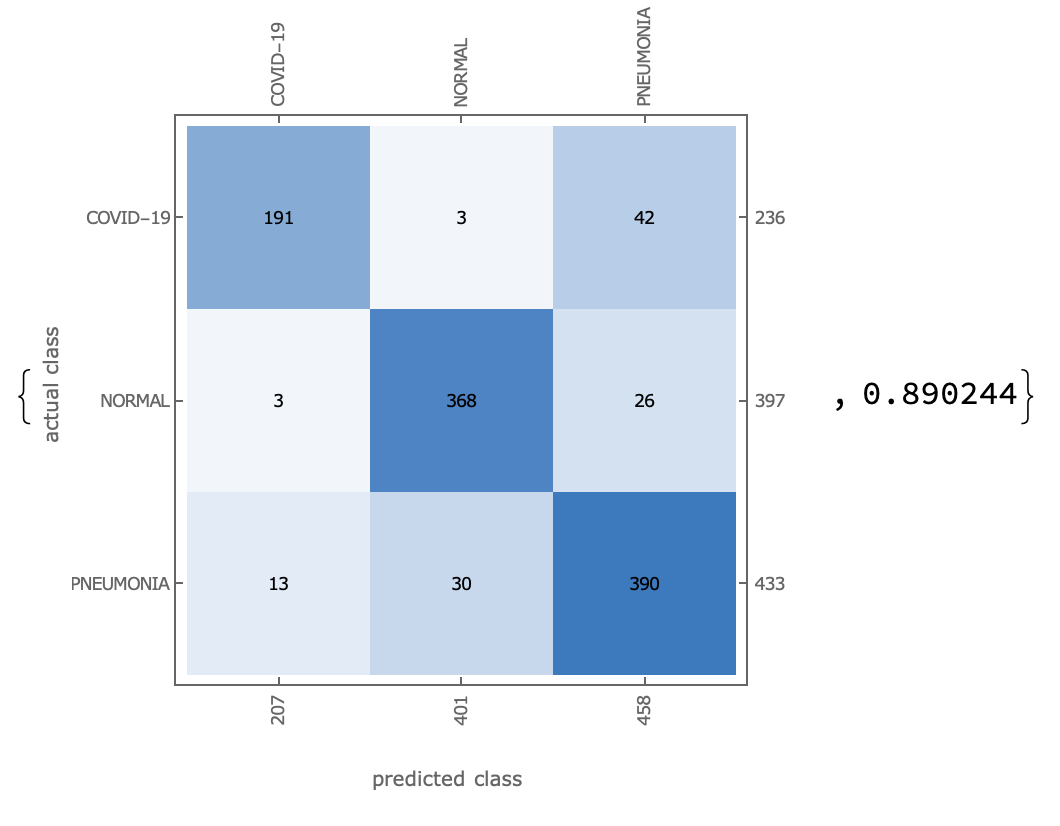
在整个测试集上,我们计算模型的准确率和混淆矩阵,可以看出模型有明显的改善,正确率为98.05%。
NetMeasurements[trainedVgg16["TrainedNet"], testDataFiles, "Accuracy"]
0.9805
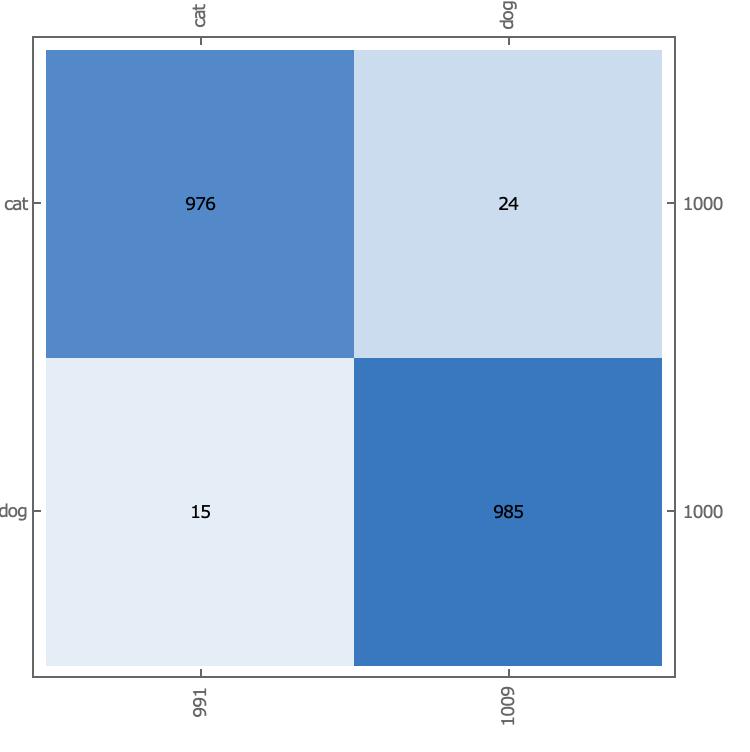
![] 目前我们使用到的模型有VGG16,ResNet-50, Mix-VGG16/ResNet-50,以下为建立ResNet-50的Mathematica代码,并单独验证catVSdog在ResNet50上我们从头训练和使用迁移学习两者的效果。
Covid-Net
- 参考论文
- 架构设计
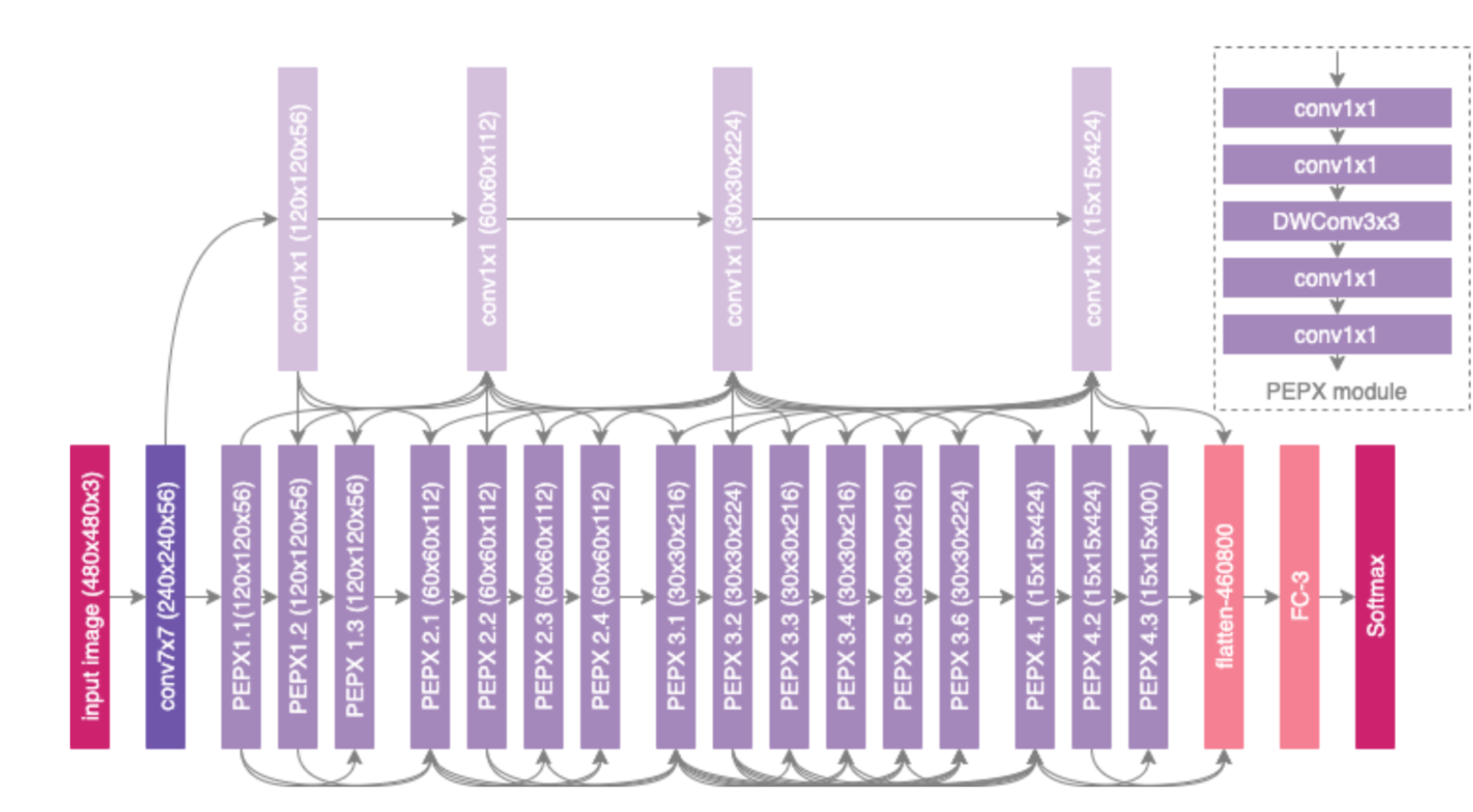
Covid-Net架构采用了Lightweight design pattern,其中采用了PEPX(projection-expansion-projection-extension)模式,每一个PEPX模块包含以下5部分:
-
First stage projection -> 1 * 1 卷积核,映射输入特征到低纬度
-
Expansion -> 1 * 1卷积核心,扩展特征属性将将特征映射到高维度
-
Depth-wise representation -> 采用3 * 3卷积核,降低计算的复杂度,同时保留重要的特征
-
Second-stage Projection -> 采用 1 * 1 卷积核,降低特征输入的维度
-
Extension -> 采用 1 * 1 卷积核心,扩展输出到高纬度,做为最后的输出
模型建立:
根据上述描述,我们来建立PEPX最基本的架构
pepxModel[inChannel_, outChannel_] := Module[
{model },
model = NetChain[{
ConvolutionLayer[Floor[ inChannel/ 2], {1, 1}],
ConvolutionLayer[IntegerPart[3 * inChannel / 4], {1, 1}],
ConvolutionLayer[IntegerPart[3 * inChannel / 4], {3, 3},
PaddingSize -> {1, 1}],
ConvolutionLayer[Floor[inChannel / 2], {1, 1}],
ConvolutionLayer[outChannel, {1, 1}]}];
model]

NetGraph[<|
"inputConv1" -> NetChain[{
ConvolutionLayer[56, {7, 7}, "Stride" -> {2, 2},
PaddingSize -> {3, 3}],
Ramp,
PoolingLayer[{3, 3}, PaddingSize -> {1, 1}]}],
"pepx1.1" -> pepxModel[56, 56],
"pepx1.2" -> pepxModel[56, 56],
"pepx1.3" -> pepxModel[56, 56],
"conv1_1x1" -> ConvolutionLayer[56, {1, 1}, "Stride" -> {2, 2}],
"conv1_1*1+pepx1.1" -> TotalLayer[],
"conv1_1*1+pepx1.{1,2}" -> TotalLayer[]
|>,
{
"inputConv1" -> "conv1_1x1" -> "pepx1.1" ,
{"pepx1.1", "conv1_1x1"} -> "conv1_1*1+pepx1.1" -> "pepx1.2",
{"pepx1.1", "conv1_1x1", "pepx1.2"} ->
"conv1_1*1+pepx1.{1,2}" -> "pepx1.3"
},
"Input" -> NetEncoder[{"Image", {480, 480}, ColorSpace -> "RGB"}]]
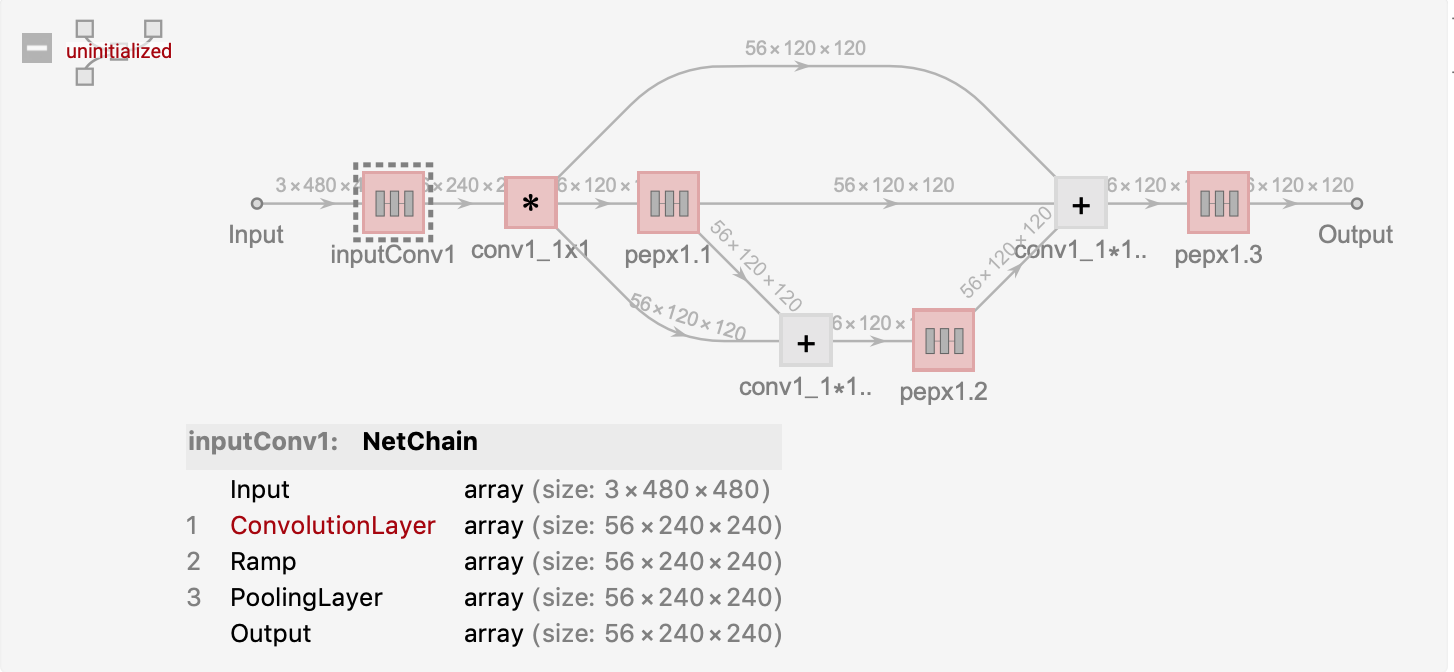
由于Covid-Net的模型搭建代码没有被公开,所以我们手动在mathematica创建测试模型。
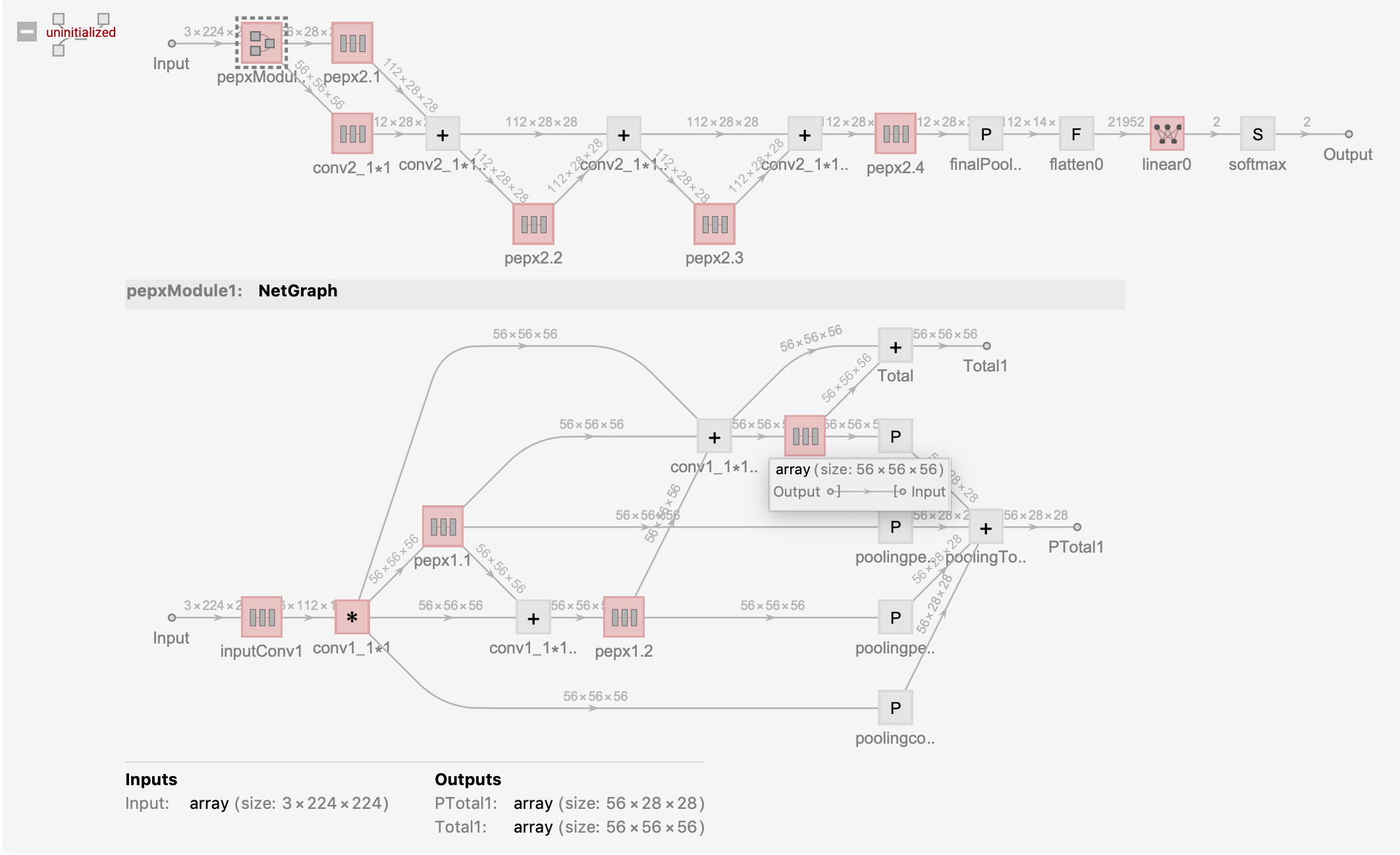
以上测试架构为为Covid-Net的PEPX{1.1,1.2,1.3},Conv1_11,Conv2_11,PEPX{2.1,2.2,2.3,2.4}的一部分计算图。
我们使用该网络来训练catVSdog,最后得到训练结果为:
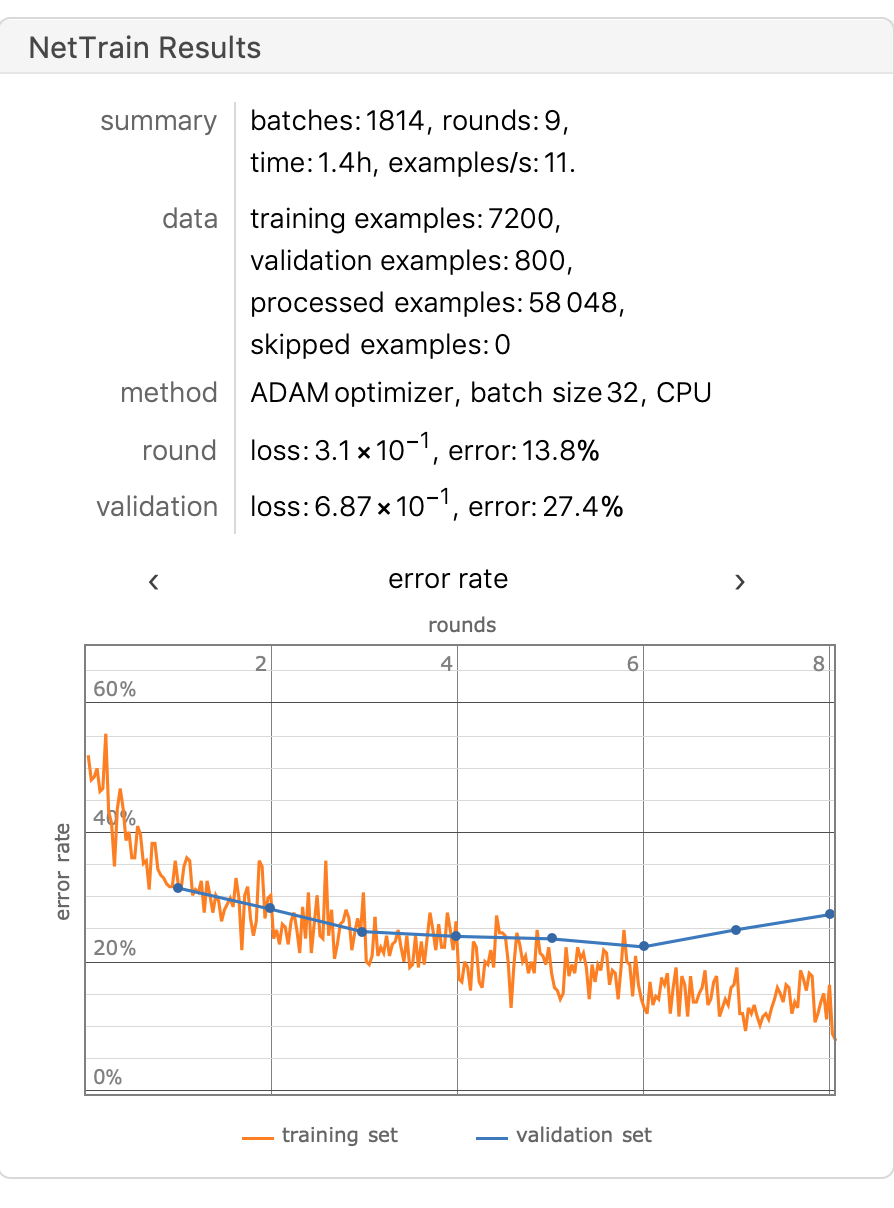
在测试集上的准确率为75.4%,图中我们可以发现从第六轮训练开始,模型训练进入了过拟合状态。
Covid-Net中使用了11的卷积核,关于使用11卷积核的功能可以查阅以下两篇文章:
1 * 1 卷积核可以用于特征数的增加和减少,比如输入的维度是(64,224,224),64个特征通道,高度和宽度分别为224,224,通过卷积核(32,1,1)处理之后,我们得到(32,224,224),32个特征通道,数据的维度依旧是(224,224)相当于我们降低了特征通道这一个维度,并没有改变数据的原始大小。
完整的Covid-Net架构在模型建立这一节里,接下来我们就要开始进入数据预处理环节,将从互联网上搜集到的X-Ray图像进行筛选和标记。
数据预处理
创建 Covidx 数据集
模型建立
Mathematica程式代码:
pepxModel[inChannel_, outChannel_] := Module[{model}, model = NetChain[
{ConvolutionLayer[Floor[inChannel/2], {1, 1}],
BatchNormalizationLayer[],
Ramp,
ConvolutionLayer[IntegerPart[3*inChannel/4], {1, 1}],
BatchNormalizationLayer[],
Ramp,
ConvolutionLayer[IntegerPart[3*inChannel/4], {3, 3},
PaddingSize -> {1, 1}],
BatchNormalizationLayer[],
Ramp,
ConvolutionLayer[Floor[inChannel/2], {1, 1}],
ConvolutionLayer[outChannel, {1, 1}],
BatchNormalizationLayer[]}];
model]
pepxModule1 := NetGraph[<|
"inputConv1" -> NetChain[{
ConvolutionLayer[56, {7, 7}, "Stride" -> {2, 2},
PaddingSize -> {3, 3}],
BatchNormalizationLayer[],
Ramp,
PoolingLayer[{3, 3}, PaddingSize -> {1, 1}]}],
(* block 1 *)
"pepx1.1" -> pepxModel[56, 56],
"pepx1.2" -> pepxModel[56, 56],
"pepx1.3" -> pepxModel[56, 56],
"conv1_1*1" ->
NetChain[{ConvolutionLayer[56, {1, 1}, "Stride" -> {2, 2}],
BatchNormalizationLayer[]}],
"conv1_1*1+pepx1.1" -> TotalLayer[],
"conv1_1*1+pepx1.{1,2}" -> TotalLayer[],
"Total" -> TotalLayer[],
"poolingpepx1.1" -> PoolingLayer[2, 2],
"poolingpepx1.2" -> PoolingLayer[2, 2],
"poolingpepx1.3" -> PoolingLayer[2, 2],
"poolingconv1_1*1" -> PoolingLayer[2, 2],
"poolingTotal" -> TotalLayer[]
|>,
{
"inputConv1" -> "conv1_1*1" -> "pepx1.1" ,
{"pepx1.1", "conv1_1*1"} -> "conv1_1*1+pepx1.1" -> "pepx1.2",
{"pepx1.1", "conv1_1*1", "pepx1.2"} ->
"conv1_1*1+pepx1.{1,2}" -> "pepx1.3",
{"conv1_1*1+pepx1.{1,2}", "pepx1.3"} ->
"Total" -> NetPort["Total1"],
{"pepx1.1" -> "poolingpepx1.1", "pepx1.2" -> "poolingpepx1.2",
"pepx1.3" -> "poolingpepx1.3",
"conv1_1*1" -> "poolingconv1_1*1"} ->
"poolingTotal" -> NetPort["PTotal1"]
}]
pepxModule2 := NetGraph[<|
"pepxModule1" -> pepxModule1,
"pepx2.1" -> pepxModel[56, 112],
"pepx2.2" -> pepxModel[112, 112],
"pepx2.3" -> pepxModel[112, 112],
"pepx2.4" -> pepxModel[112, 112],
"conv2_1*1" -> NetChain[{
ConvolutionLayer[112, {1, 1}],
BatchNormalizationLayer[],
Ramp,
PoolingLayer[2, 2]}],
"conv2_1*1+pepx2.1" -> TotalLayer[],
"conv2_1*1+pepx2.{1,2}" -> TotalLayer[],
"conv2_1*1+pepx2.{1,2,3}" -> TotalLayer[],
"Total" -> TotalLayer[],
"PTotal" -> TotalLayer[],
"poolingpepx2.1" -> PoolingLayer[2, 2],
"poolingpepx2.2" -> PoolingLayer[2, 2],
"poolingpepx2.3" -> PoolingLayer[2, 2],
"poolingpepx2.4" -> PoolingLayer[2, 2],
"poolingconv2_1*1" -> PoolingLayer[2, 2]
|>,
{
NetPort["pepxModule1", "Total1"] -> "conv2_1*1",
NetPort["pepxModule1", "PTotal1"] -> "pepx2.1",
{"conv2_1*1", "pepx2.1"} -> "conv2_1*1+pepx2.1" -> "pepx2.2",
{"conv2_1*1+pepx2.1", "pepx2.2"} ->
"conv2_1*1+pepx2.{1,2}" -> "pepx2.3",
{"conv2_1*1+pepx2.{1,2}", "pepx2.3"} ->
"conv2_1*1+pepx2.{1,2,3}" -> "pepx2.4" ,
{"conv2_1*1+pepx2.{1,2,3}", "pepx2.4"} ->
"Total" -> NetPort["Total2"],
{"pepx2.1" -> "poolingpepx2.1", "pepx2.2" -> "poolingpepx2.2",
"pepx2.3" -> "poolingpepx2.3", "pepx2.4" -> "poolingpepx2.4",
"conv2_1*1" -> "poolingconv2_1*1"} ->
"PTotal" -> NetPort["PTotal2"]
}]
pepxModule3 := NetGraph[<|
"pepxModule2" -> pepxModule2,
"conv3_1*1" -> NetChain[{
ConvolutionLayer[224, {1, 1}],
BatchNormalizationLayer[],
Ramp,
PoolingLayer[2, 2]}],
"pepx3.1" -> pepxModel[112, 224],
"pepx3.2" -> pepxModel[224, 224],
"pepx3.3" -> pepxModel[224, 224],
"pepx3.4" -> pepxModel[224, 224],
"pepx3.5" -> pepxModel[224, 224],
"pepx3.6" -> pepxModel[224, 224],
"conv3_1*1+pepx3.1" -> TotalLayer[],
"conv3_1*1+pepx3{1,2}" -> TotalLayer[],
"conv3_1*1+pepx3{1,2,3}" -> TotalLayer[],
"conv3_1*1+pepx3{1,2,3,4}" -> TotalLayer[],
"conv3_1*1+pepx3{1,2,3,4,5}" -> TotalLayer[],
"Total" -> TotalLayer[],
"PTotal" -> TotalLayer[],
"poolingpepx3.1" -> PoolingLayer[2, 2],
"poolingpepx3.2" -> PoolingLayer[2, 2],
"poolingpepx3.3" -> PoolingLayer[2, 2],
"poolingpepx3.4" -> PoolingLayer[2, 2],
"poolingpepx3.5" -> PoolingLayer[2, 2],
"poolingpepx3.6" -> PoolingLayer[2, 2],
"poolingconv3_1*1" -> PoolingLayer[2, 2]
|>,
{
NetPort["pepxModule2", "Total2"] -> "conv3_1*1",
NetPort["pepxModule2", "PTotal2"] -> "pepx3.1",
{"pepx3.1", "conv3_1*1"} -> "conv3_1*1+pepx3.1" -> "pepx3.2",
{"conv3_1*1+pepx3.1", "pepx3.2"} ->
"conv3_1*1+pepx3{1,2}" -> "pepx3.3",
{"conv3_1*1+pepx3{1,2}" , "pepx3.3"} ->
"conv3_1*1+pepx3{1,2,3}" -> "pepx3.4",
{"conv3_1*1+pepx3{1,2,3}", "pepx3.4"} ->
"conv3_1*1+pepx3{1,2,3,4}" -> "pepx3.5",
{ "conv3_1*1+pepx3{1,2,3,4}" , "pepx3.5"} ->
"conv3_1*1+pepx3{1,2,3,4,5}" -> "pepx3.6",
{"conv3_1*1+pepx3{1,2,3,4,5}", "pepx3.6"} ->
"Total" -> NetPort["Total3"],
{"pepx3.1" -> "poolingpepx3.1", "pepx3.2" -> "poolingpepx3.2",
"pepx3.3" -> "poolingpepx3.3", "pepx3.4" -> "poolingpepx3.4",
"pepx3.5" -> "poolingpepx3.5", "pepx3.6" -> "poolingpepx3.6",
"conv3_1*1" -> "poolingconv3_1*1"} ->
"PTotal" -> NetPort["PTotal3"]
}]
pepxModule4 := NetGraph[<|
"pepxModule3" -> pepxModule3,
"conv4_1*1" -> NetChain[{
ConvolutionLayer[424, {1, 1}],
BatchNormalizationLayer[],
Ramp,
PoolingLayer[2, 2]}],
"pepx4.1" -> pepxModel[224, 424],
"pepx4.2" -> pepxModel[424, 424],
"pepx4.3" -> pepxModel[424, 424],
"conv4_1*1+pepx4.1" -> TotalLayer[],
"conv4_1*1+pepx4.{1,2}" -> TotalLayer[],
"conv4_1*1+pepx4.{1,2,3}" -> TotalLayer[]
|>,
{
NetPort["pepxModule3", "Total3"] -> "conv4_1*1",
NetPort["pepxModule3", "PTotal3"] -> "pepx4.1",
{"pepx4.1", "conv4_1*1"} -> "conv4_1*1+pepx4.1" -> "pepx4.2",
{"conv4_1*1+pepx4.1", "pepx4.2"} ->
"conv4_1*1+pepx4.{1,2}" -> "pepx4.3",
{"conv4_1*1+pepx4.{1,2}", "pepx4.3"} -> "conv4_1*1+pepx4.{1,2,3}"
}]
covidNet =
NetInitialize[
NetGraph[<|
"imageAug" -> ImageAugmentationLayer[{224, 224}],
"pepxPipelines" -> pepxModule4,
"fc0" -> FlattenLayer[],
"topLayers" -> NetChain[{
LinearLayer[1024],
Ramp,
DropoutLayer[],
LinearLayer[256],
Ramp,
LinearLayer[2],
SoftmaxLayer[]}]
|>,
{
"imageAug" -> "pepxPipelines" -> "fc0" -> "topLayers"
},
"Input" -> NetEncoder[{"Image", {224, 224}, ColorSpace -> "RGB"}],
"Output" -> NetDecoder[{"Class", {"cat", "dog"}}]],
Method -> {"Xavier", "Distribution" -> "Uniform"}]
模型架构图如下:
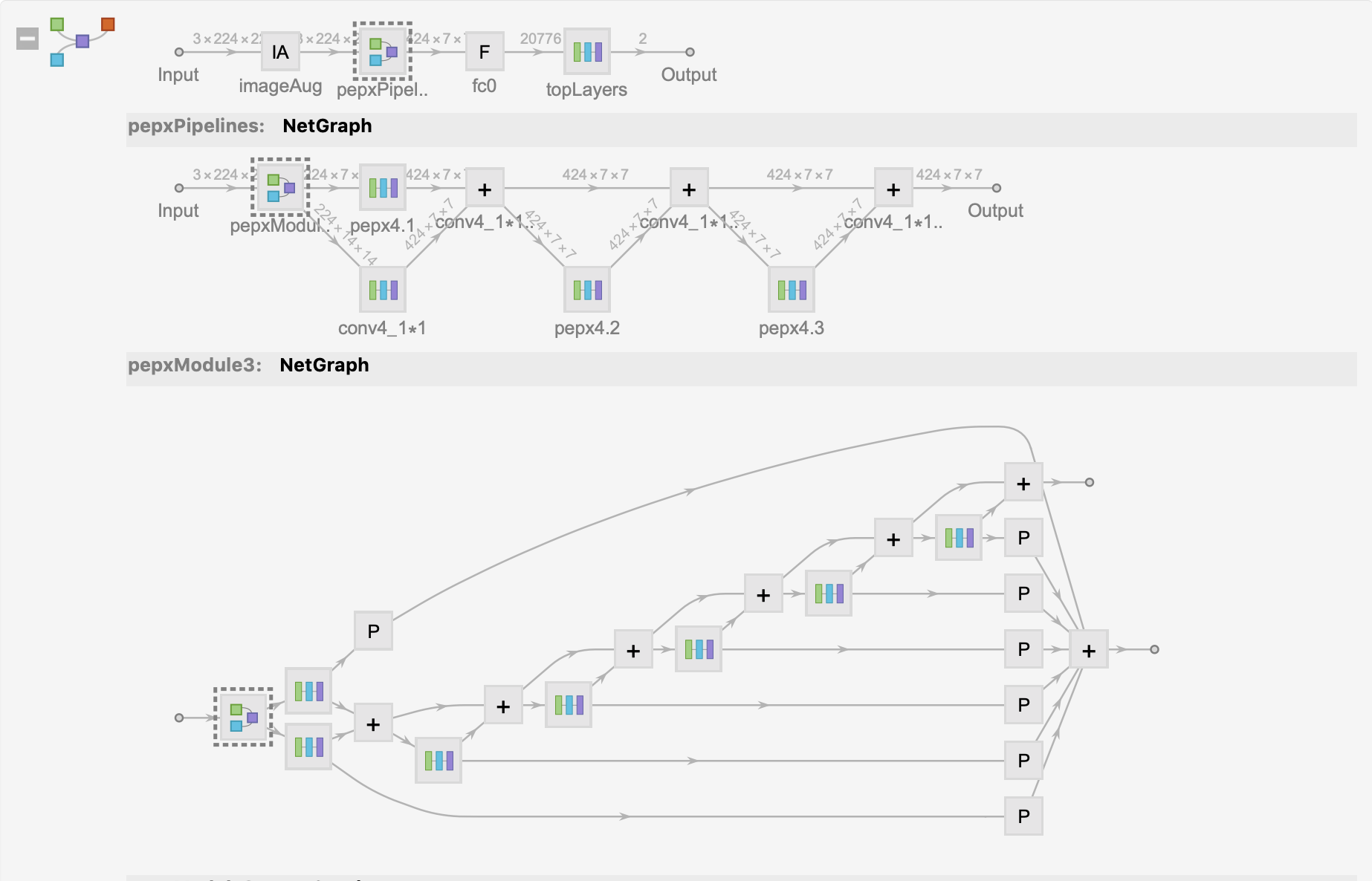
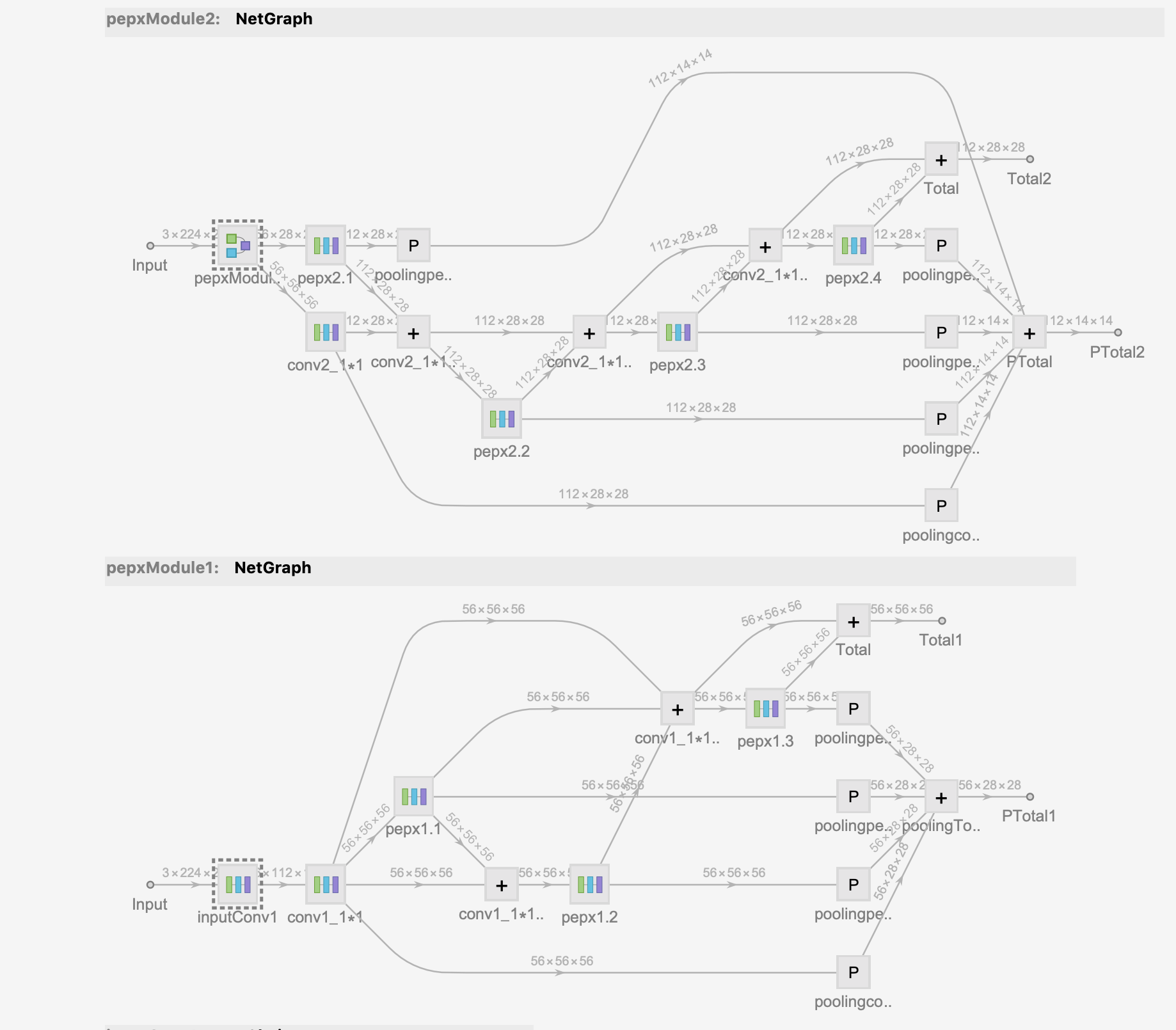
最后在CatDog数据集上用自己的笔记本训练该模型🔟轮之后得到的正确率约为80%
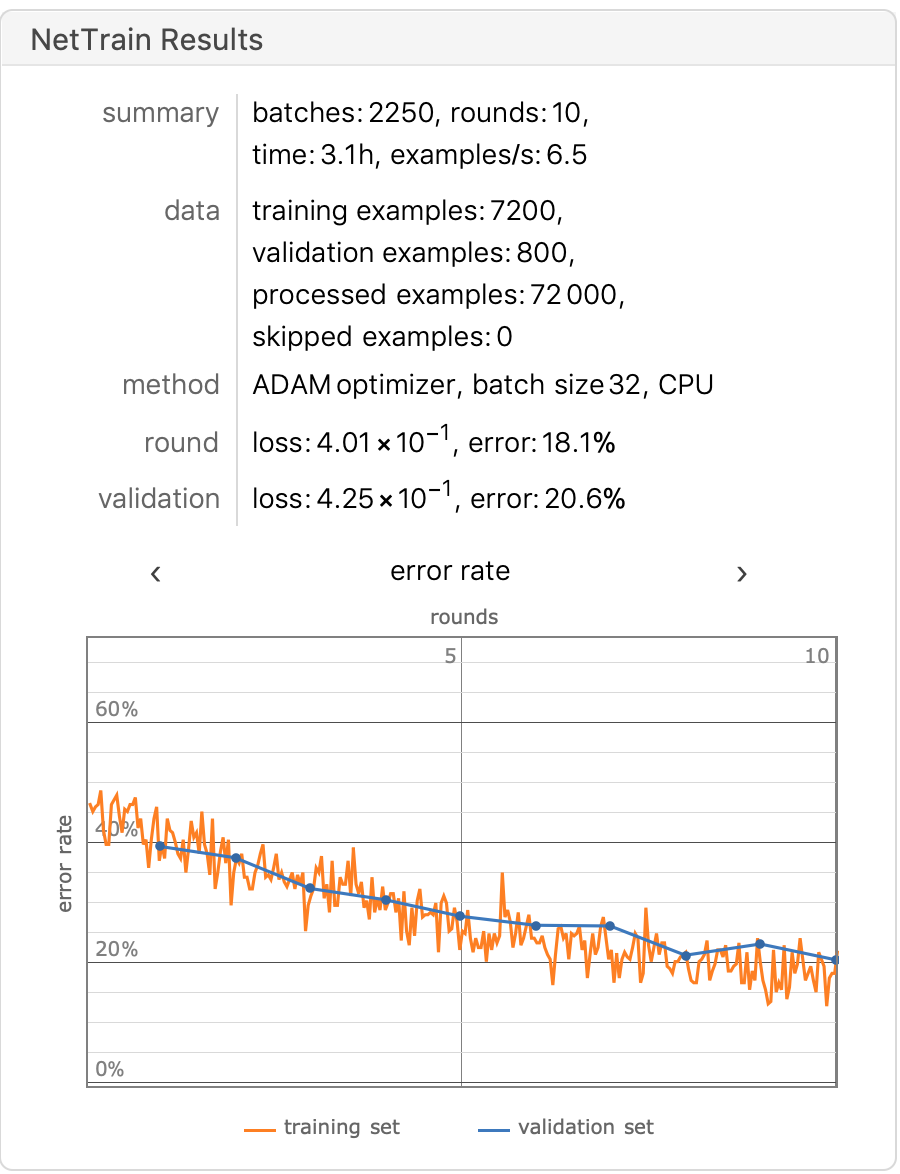
最后我们在工作站上训练该模型,DogCat数据集增加到25000张图片以增强模型的泛化能力,训练🔟轮之后模型的准确率接近92%。

最后我们将收集到的xRay images进行分类,标签为 labels = {“COVID-19”, “NORMAL”, “PNEUMONIA”}
数据集分别为:ieee8023Data,Figure1-COVID-chest-x-ray-dataset,ActualmedDataSets,radiography datasets,总数据集数量为3551张xray,其中covid-19占763张。
将数据集分为训练集合和验证集合之后,我们开始进入模型训练阶段,其中训练集合中covid-19数量为676张,验证集中covid-19为87张。
训练模型
最终模型架构如下:
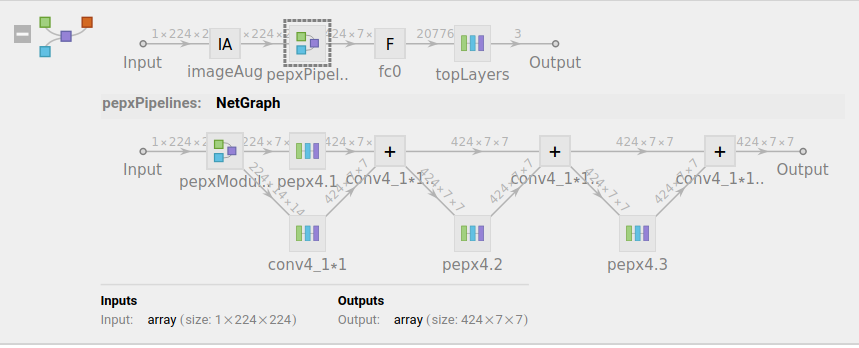
covidNetTrained =
NetTrain[covidNet, traingDataSets, All, TargetDevice -> "GPU",
ValidationSet -> validationDataSets,
TrainingProgressCheckpointing -> {"Directory", dir},
TrainingProgressReporting -> "Panel", BatchSize -> 32,
TrainingStoppingCriterion -> <|"Criterion" -> "Loss",
"Patience" -> 5|>]
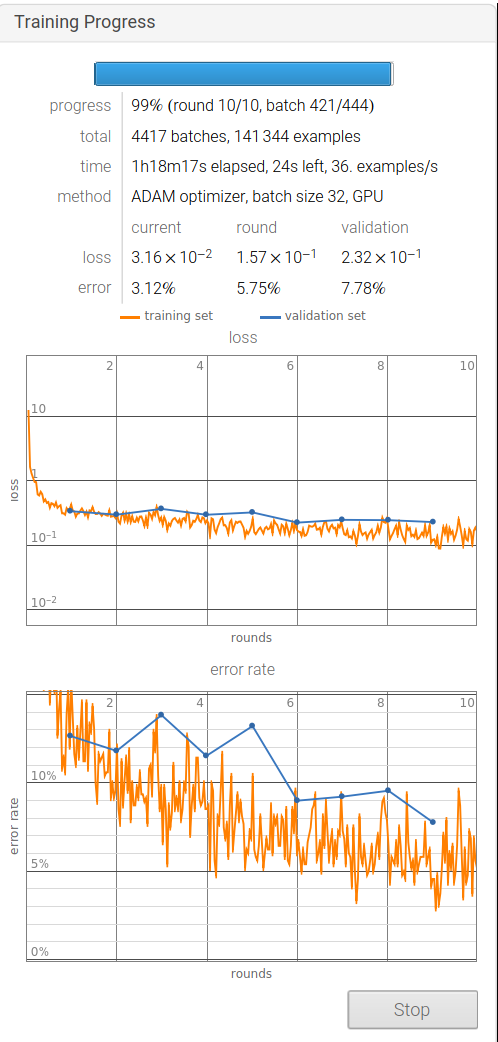
最终的训练结果:
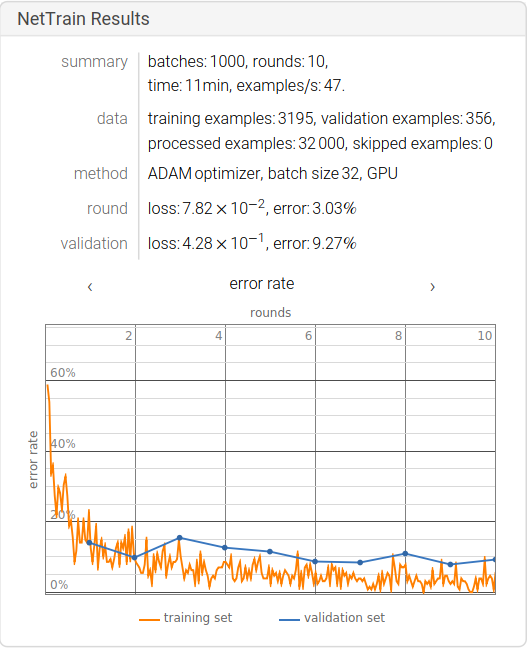
从中可以发现模型的准确率大概在90%,由于数据集容量较小,所以对该模型训练的结果还有很大的改进空间,接下来我们需要增强数据集,可以在网上继续搜集数据或者对当前的数据图片做缩平移旋转等变换,变换可以分为(Flip, Rotation, Scale, Crop, Translation, Gaussian Noise)
数据集增强
genDatasets[origindataset_] :=
Module[{file, label, img, basename, dims},
file = Keys[origindataset];
label = Values[origindataset];
basename = FileBaseName[List @@ file[[1]]];
If[Not@DirectoryQ[cleandatasetsDir <> label],
CreateDirectory[cleandatasetsDir <> label]];
img = Import@file;
(* rotate *)
Export[cleandatasetsDir <> label <> "/" <> basename <> "_rotate" <>
".png" ,
ImageRotate[img, RandomReal[] * 2 \[Pi],
Background -> Transparent]];
(* reflect *)
Export[cleandatasetsDir <> label <> "/" <> basename <> "_reflect" <>
".png",
ImageReflect[img, RandomChoice[{Bottom, Top, Left}]]];
(* crop *)
Export[cleandatasetsDir <> label <> "/" <> basename <> "_crop" <>
".png",
ImageCrop[
img, {ImageDimensions[img][[1]] / RandomReal[{1, 1.5}],
ImageDimensions[img][[2]]/ RandomReal[{1, 1.5}]}]];
(* blur *)
Export[cleandatasetsDir <> label <> "/" <> basename <> "_blur" <>
".png",
GaussianFilter[img, RandomInteger[{1, 2}]]];
(* origin *)
Export[cleandatasetsDir <> label <> "/" <> basename <> ".png",
img];
]
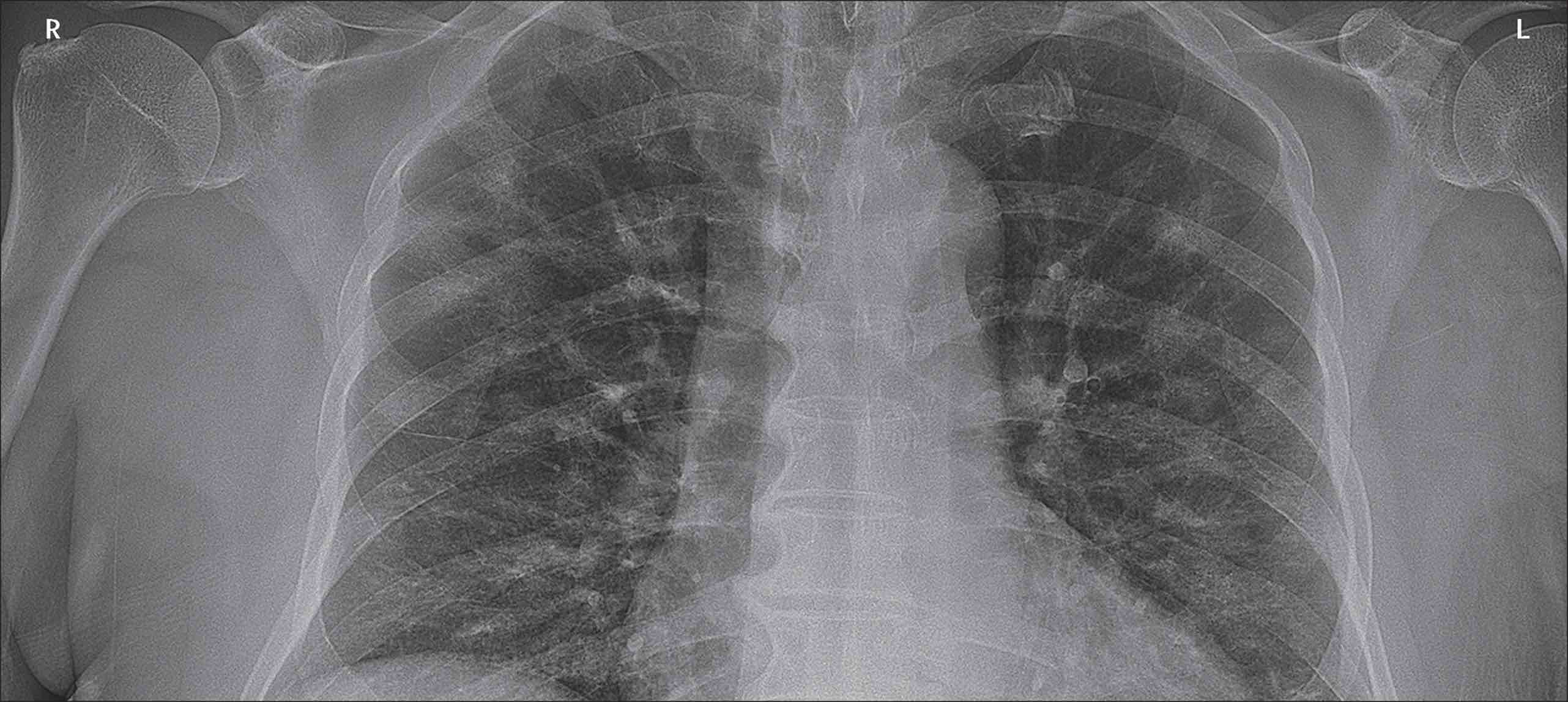
我们需要对原有的图像进行旋转和反射,从而能够更好的泛化模型,生成函数包含在最后的代码文件中,利用上述函数,我们对图像进行裁切旋转和翻转及模糊处理。
原图像:
随机旋转图像
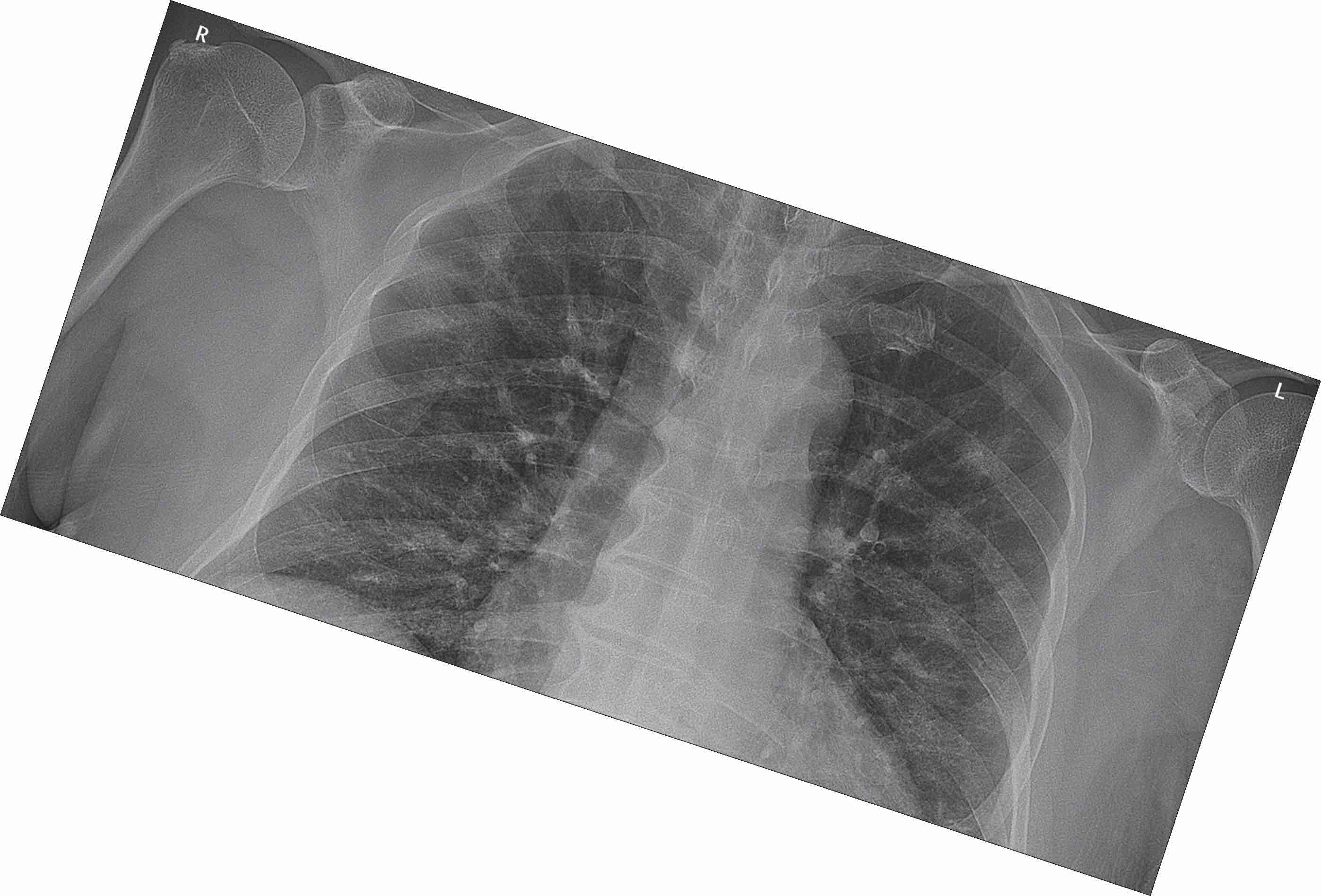
反射图像
最后将这些生成好的图像合并进训练和验证集测试集中。
测试模型
在增强数据集的基础上对模型进行训练,训练时长限定为1小时,最后的结果如下:
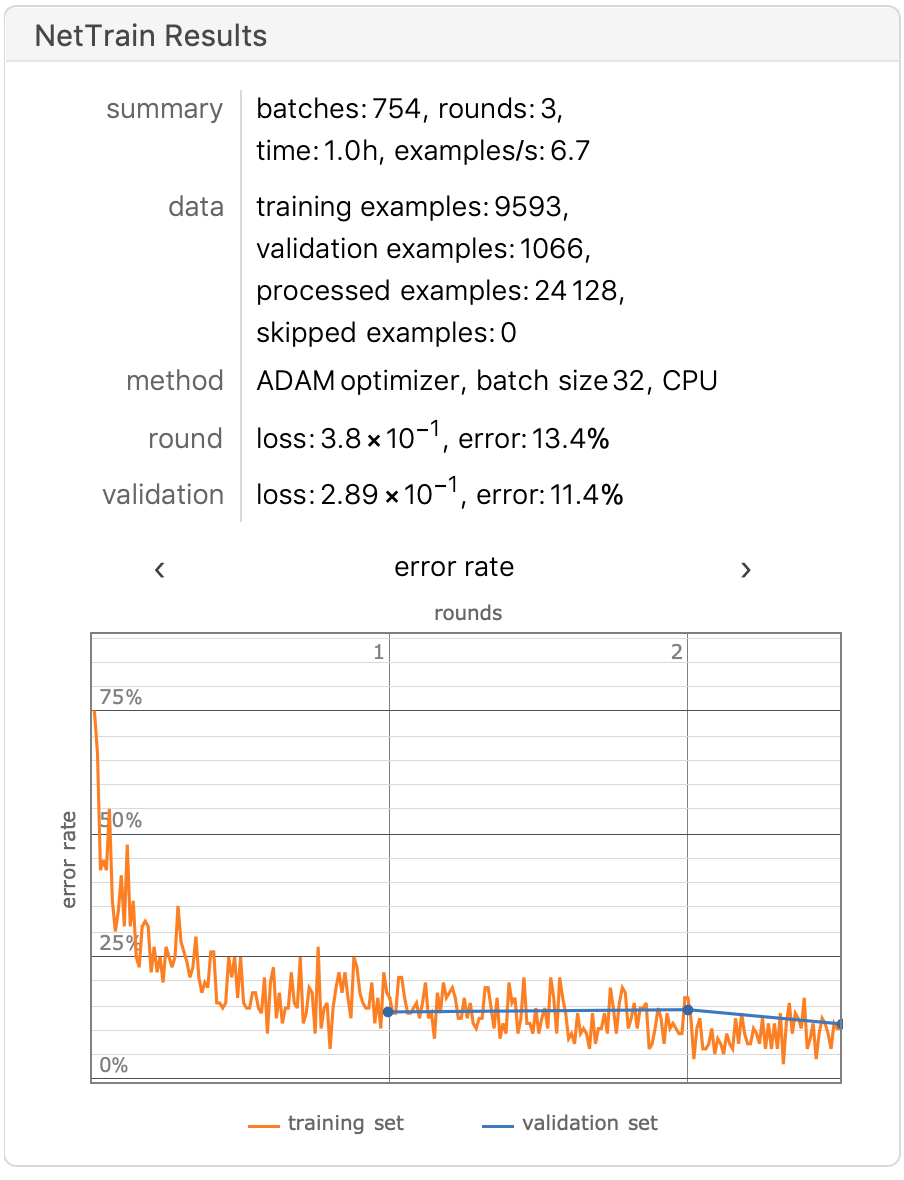
准确率接近90%
最后设定EPOCHS=10,batch_size=32,划分训练集:验证集:测试集为8:1:1,训练结果如下:
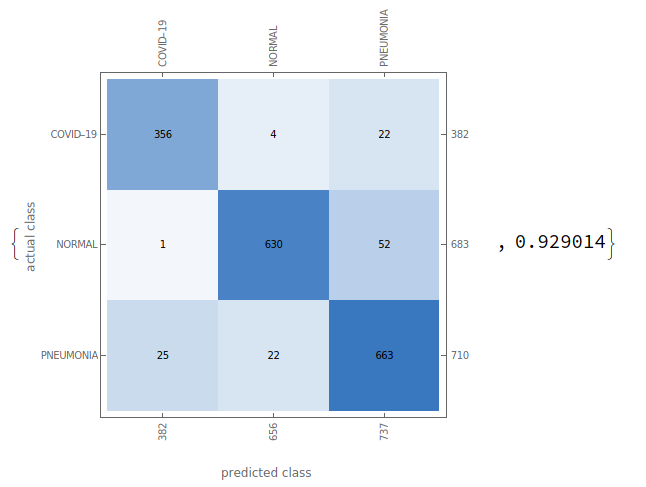
我们采用Recall Precision Accuracy F1-Score来度量我们判断该模型对SARS-COV-2预测的能力是否有效,计算公式如下:
TP: True Positive FP: False Positive TN: True Negative FN: False Negative
Recall = TP / (TP + FN)
Precision = TP / (TP + FP)
Accuracy = (TP + TN) / (TP + TN + FP + FN)
F1-Score = 2 * (Recall * Precision) / (Recall + Precision)
结果如下:
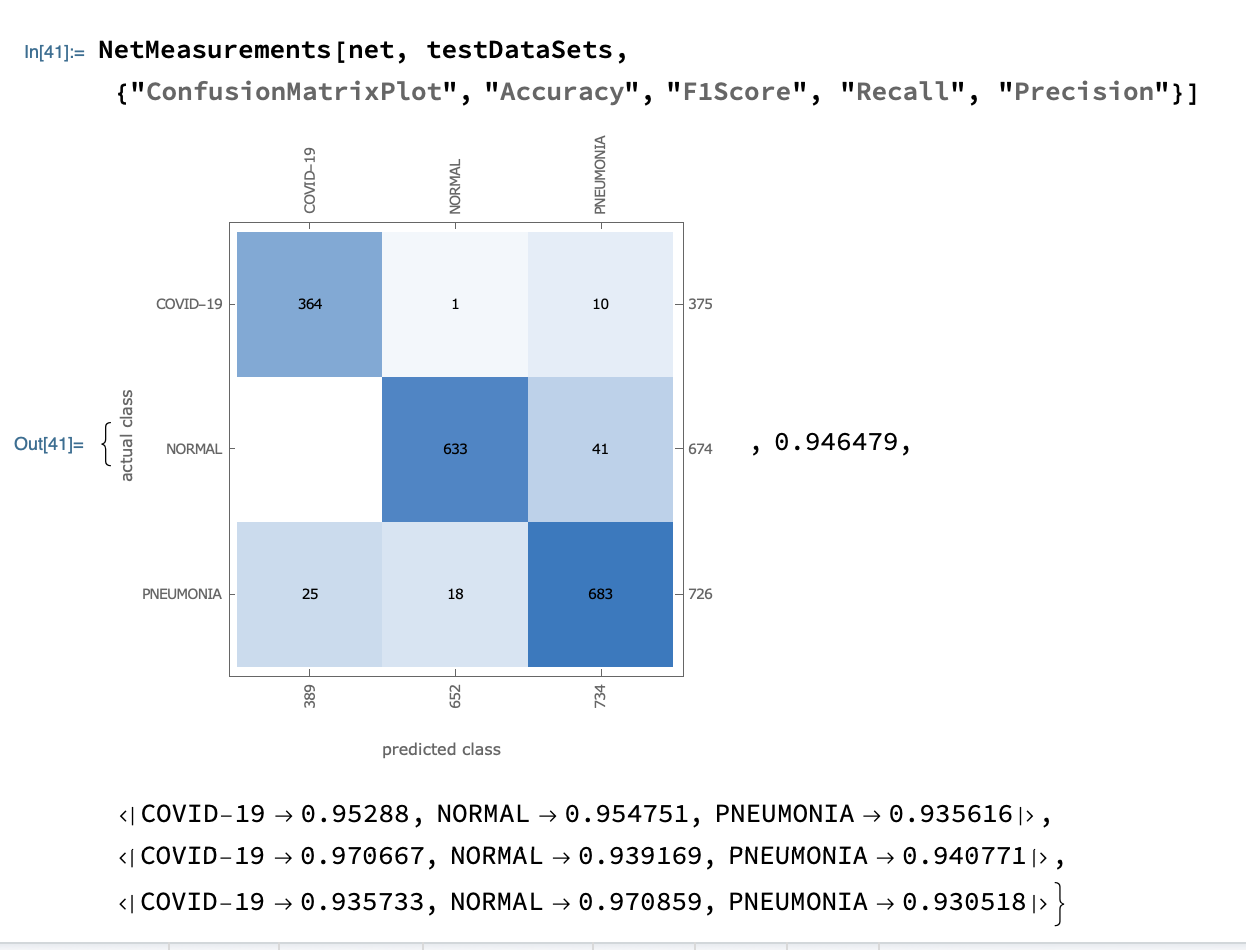
Covid-19的召回率为97%,意味着在所有的Covid19患者中诊断为患病的准确率为97%
Covid-19的精准率为93%,意味着在所有的样本中能够预测出是Covid-19的准确率为93%
最后的F1-Score的得分为95%。
Covid-Net与ResNet-50迁移学习对比
resNet = NetModel["ResNet-50 Trained on ImageNet Competition Data"];
featureNet = NetTake[resNet, {1, -4}];
covidResNet = NetChain[<|
"featuresNet" -> featureNet,
"f0" -> FlattenLayer[],
"linear1" -> LinearLayer[3],
"soft" -> SoftmaxLayer[]|>,
"Input" -> NetEncoder[{"Image", {224, 224}, ColorSpace -> "RGB"}],
"Output" -> NetDecoder[{"Class", labels}]];
dir = CreateDirectory["/Volumes/DataSets/transfermodels"];
covidTrainedNet =
NetTrain[covidResNet, traingDataSets,
ValidationSet -> validationDataSets,
LearningRateMultipliers -> {"featuresNet" -> 0, _ -> 1},
TrainingProgressCheckpointing -> {"Directory", dir},
TrainingStoppingCriterion -> <|"Criterion" -> "Loss",
"Patience" -> 4|>,
BatchSize -> 32]
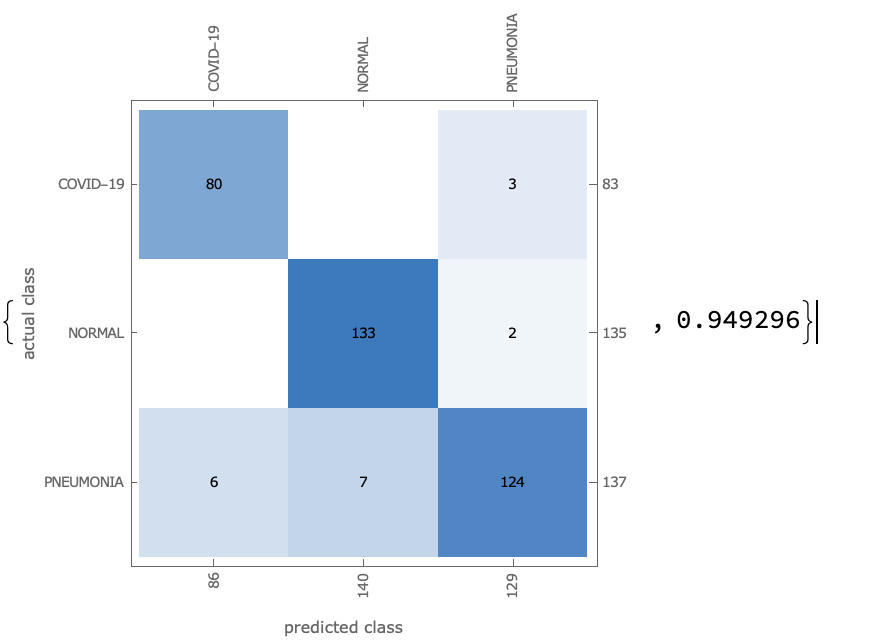
NetMeasurements[covidTrainedNet, validationDataSets, \
{"ConfusionMatrixPlot", "Accuracy"}]
迁移学习之后ResNet模型的结果:
部署模型
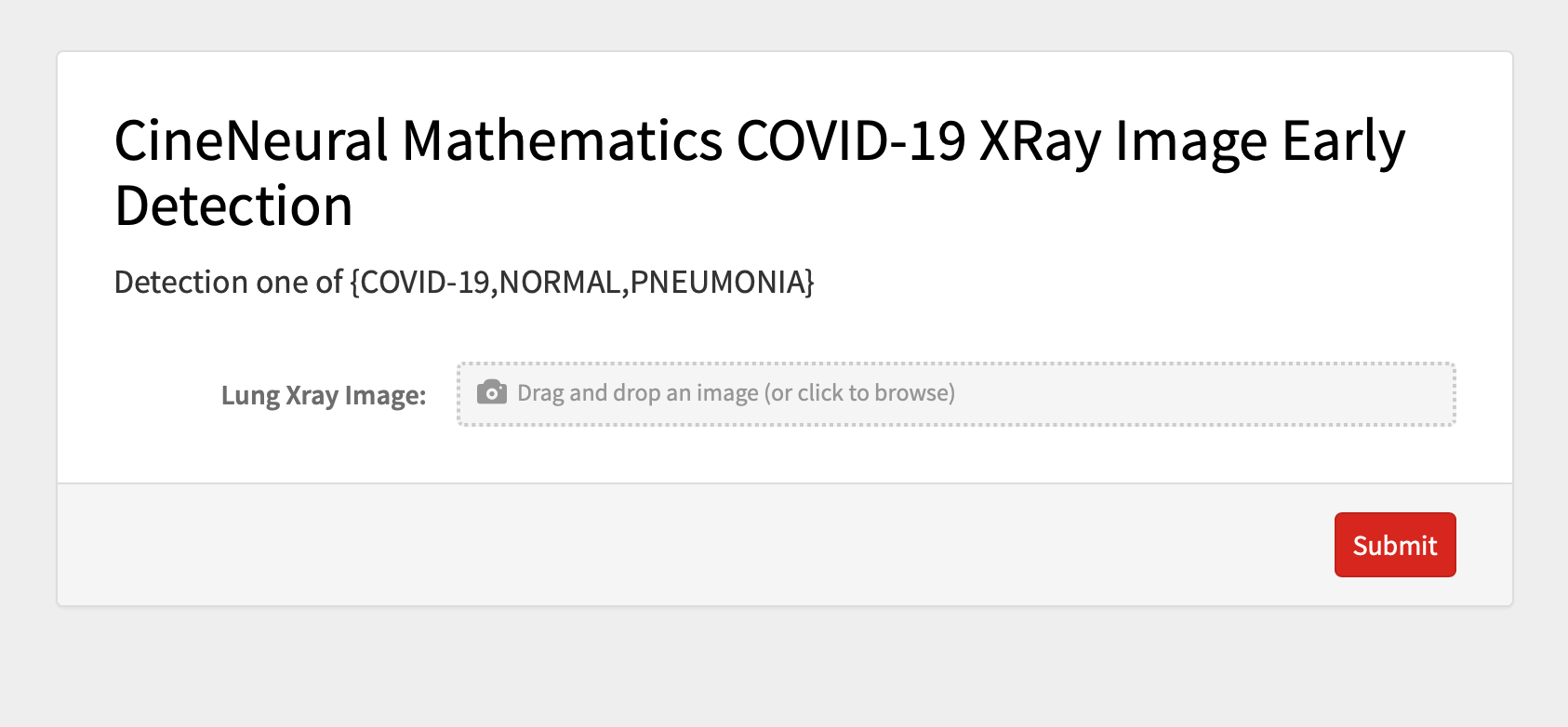
我们将使用Wolfram Cloud去部署我们的covidResNet和covid-Net。
(* 将训练好的模型上传至Wolfram Cloud *)
netlink = CloudExport[covidTrainedNet, "MX", Permissions -> "Public"]
(* 部署页面和处理函数到Cloud *)
CloudDeploy[
FormPage[{{"image", "Lung Xray Image: "} -> "Image"},
With[{net = CloudImport@netlink}, net[#image]] &,
AppearanceRules -> <|
"Title" ->
"CineNeural Mathematics COVID-19 XRay Image Early Detection",
"Description" -> "Detection one of {COVID-19,NORMAL,PNEUMONIA}"|>],
Permissions -> "Public"]
页面如下:
CineNeural Mathematics COVID-19 XRay Image Early Detection
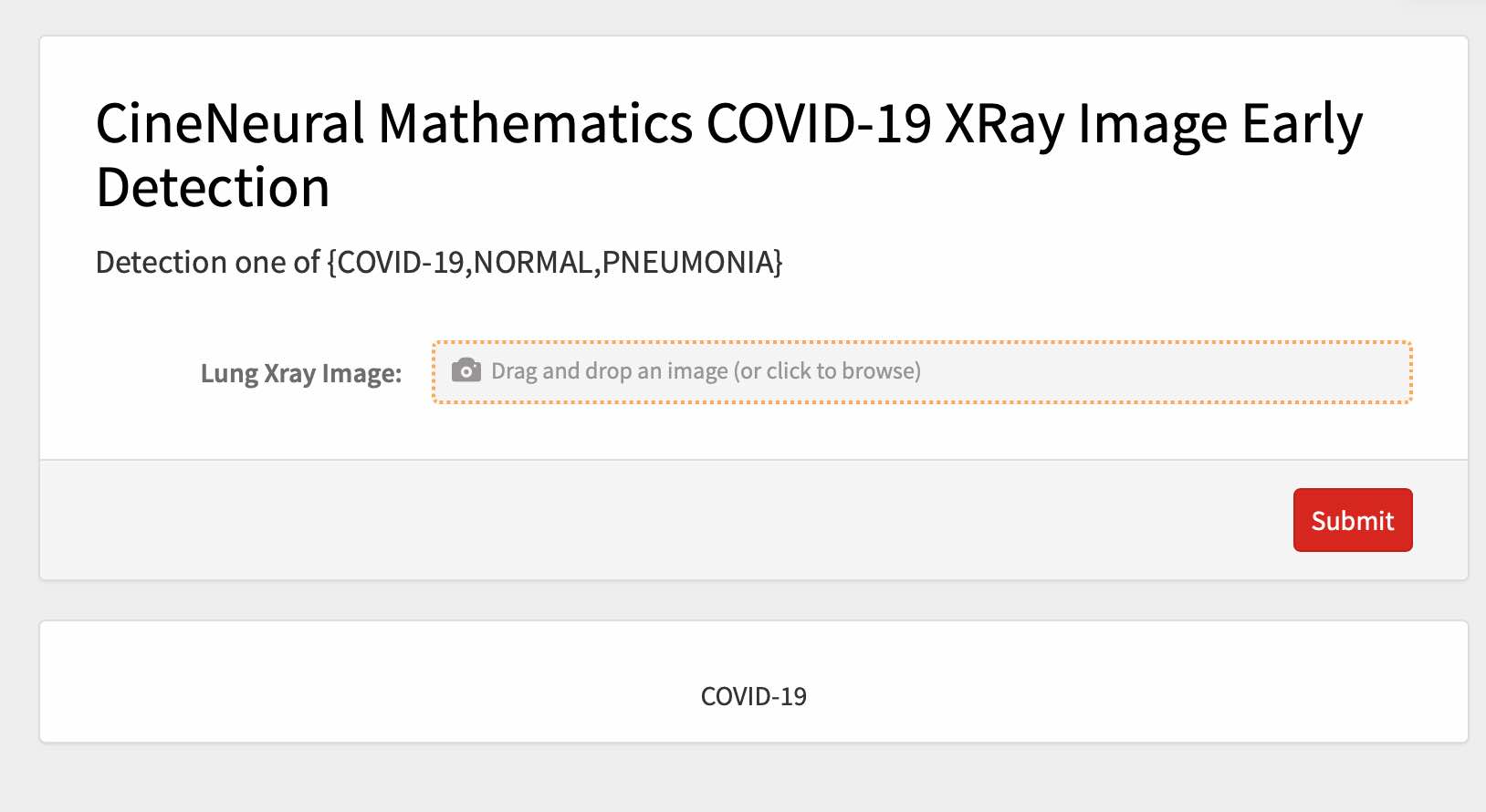
部署模型到本地Coral dev Board
将模型部署到本地,是未来深度学习的趋势,这一节我们将结合Tensorflow和Mathematica,在google coral dev board上运行训练好的模型。